




パブリックドメインおよびオープンライセンスのコンテンツのみで構成された約8TBの巨大データセット「Common Pile v0.1」をAI研究機関・EleutherAIがリリース

非営利のAI研究組織であるEleutherAIがトロント大学やHugging Faceなどと共同で、パブリックドメインおよびオープンライセンスのコンテンツのみで構成されるデータセット「Common Pile v0.1」を公開しました。このCommon Pile v0.1でトレーニングされたAIモデル「Comma v0.1-1T」「Comma v0.1-2T」は、「著作権で保護された無許可のデータを使用して開発されたモデルと同等の性能を発揮した」とのことです。
[2506.05209] The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
https://arxiv.org/abs/2506.05209
The Common Pile v0.1 | EleutherAI Blog
https://blog.eleuther.ai/common-pile/
The Common Pile v0.1
https://huggingface.co/blog/stellaathena/common-pile
OpenAIを含むAI企業は、 AIモデルのトレーニングの手法をめぐって訴訟に巻き込まれています。
OpenAIの著作権訴訟でChatGPTのトレーニングデータが一部の人間に開示されることが決定、オフライン・記録機器持ち込み禁止の厳重警備体制 - GIGAZINE

AIトレーニングに使われているデータセットは、書籍や研究ジャーナルといった著作権で保護された資料を含むウェブ上の情報をスクレイピングして構築されていることがほとんど。そのため、生成AIには著作権侵害のリスクがあるという声が上がっています。一部のAI企業は特定のコンテンツプロバイダーとライセンス契約を結んでいるものの、大半の企業は著作権で保護された著作物を許可なく学習させた場合、米国の法理であるフェアユースの原則によって責任を免れると主張しています。
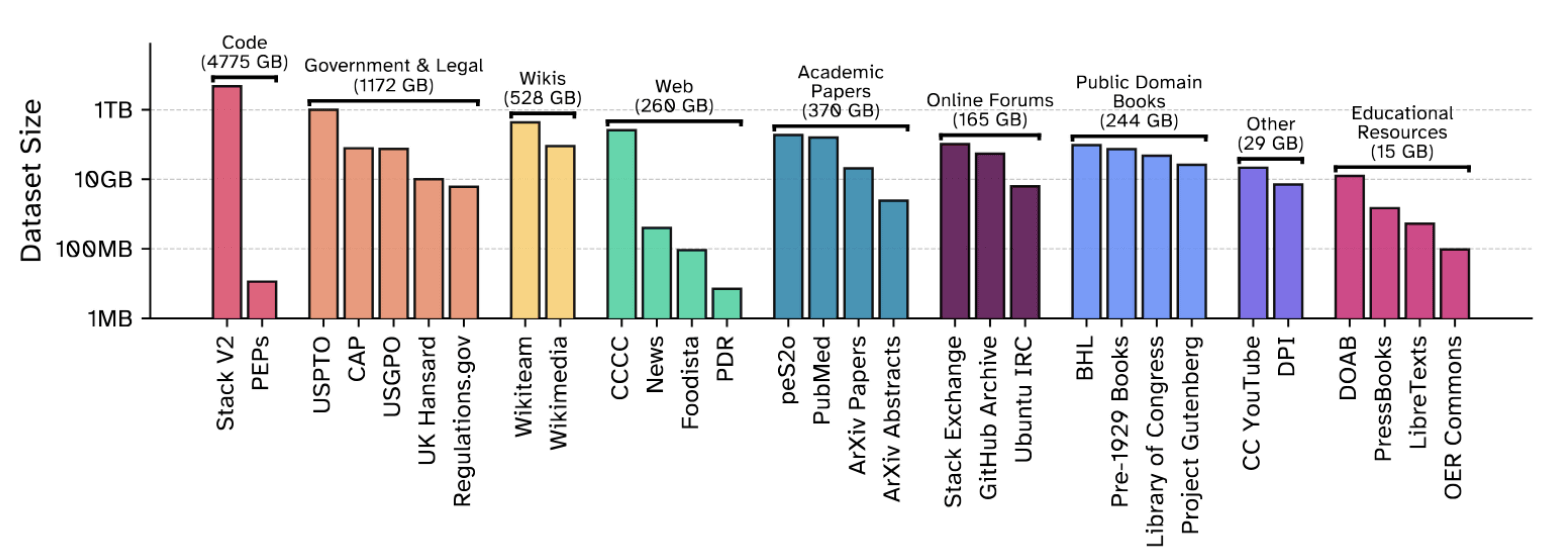
Common Pile v0.1は、EleutherAIが2020年にリリースした800GBのデータセット「The Pile」の後継に当たります。データセットは30種類で、その総量は8TBに及びます。その内訳は以下の通り。
・コード(4775GB)
・法律や政府文書(1172GB)
・Wikipediaなどの文章(528GB)
・学術論文(370GB)
・パブリックドメインの書籍(244GB)
・その他、オンラインフォーラムやYouTube字幕、教育リソースなど
EleutherAIはCommon Pile v0.1の目的と理念として、「透明性と科学的厳密性の確保」「オープン性の推進」「オープンなライセンスへの準拠」を挙げています。特にオープンなライセンスへの準拠については、オープンナレッジ財団が定義する「オープンライセンス」の基準に依拠しており、これは「いかなる人物でも、いかなる目的のためにも、使用、研究、修正、再配布が許可されている」ことを意味します。
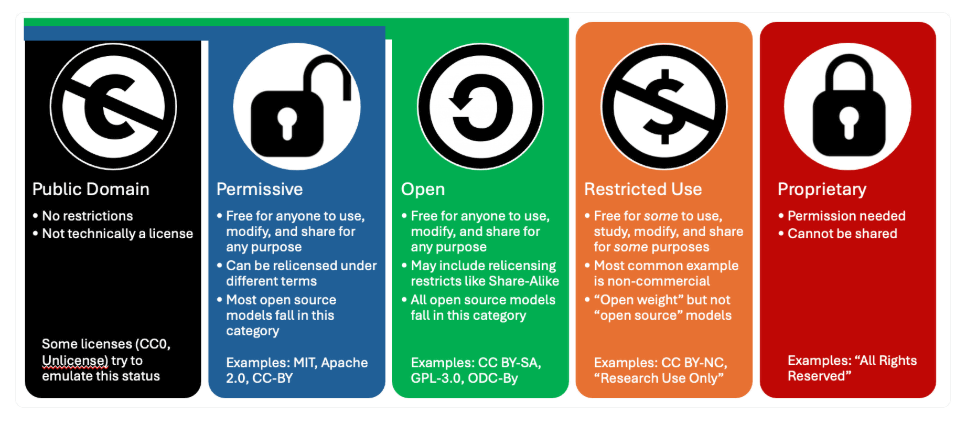
収集するデータがオープンライセンスか否かは、自動化ツールだけに頼らず、信頼できる情報源のメタデータや手動でのキュレーションによって確認されています。
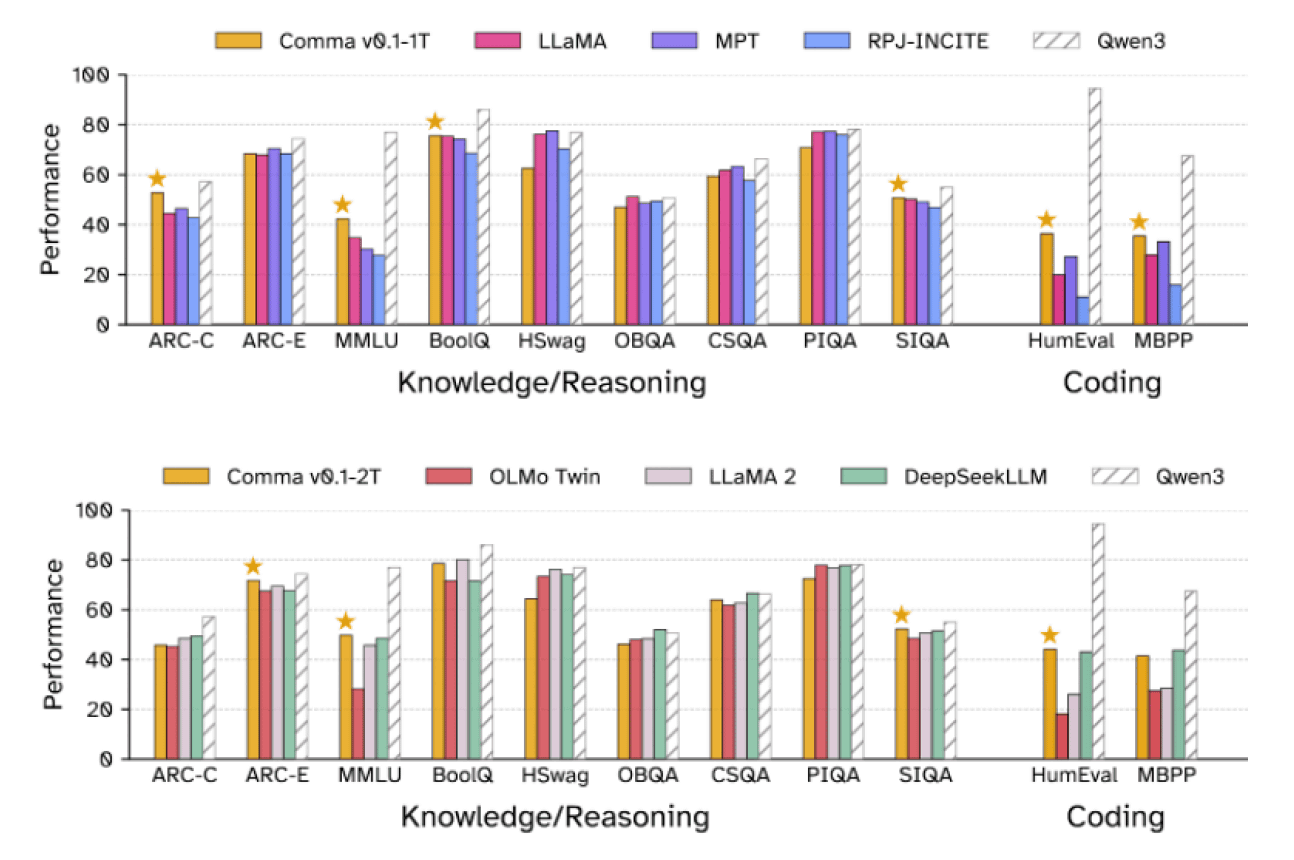
また、EleutherAIはCommon Pileでトレーニングしたパラメータ数70億の言語モデル「Comma v0.1」が、ライセンスのないデータでトレーニングされた主要なモデルに匹敵する性能を持つことを示しました。以下はComma v0.1-1T(上)とComma v0.1-2T(下)のベンチマーク結果を他のAIモデルと比較したグラフ。Comma v0.1-1Tは1兆個のトークンで、Comma v0.1-2Tは2兆個のトークンでトレーニングされています。
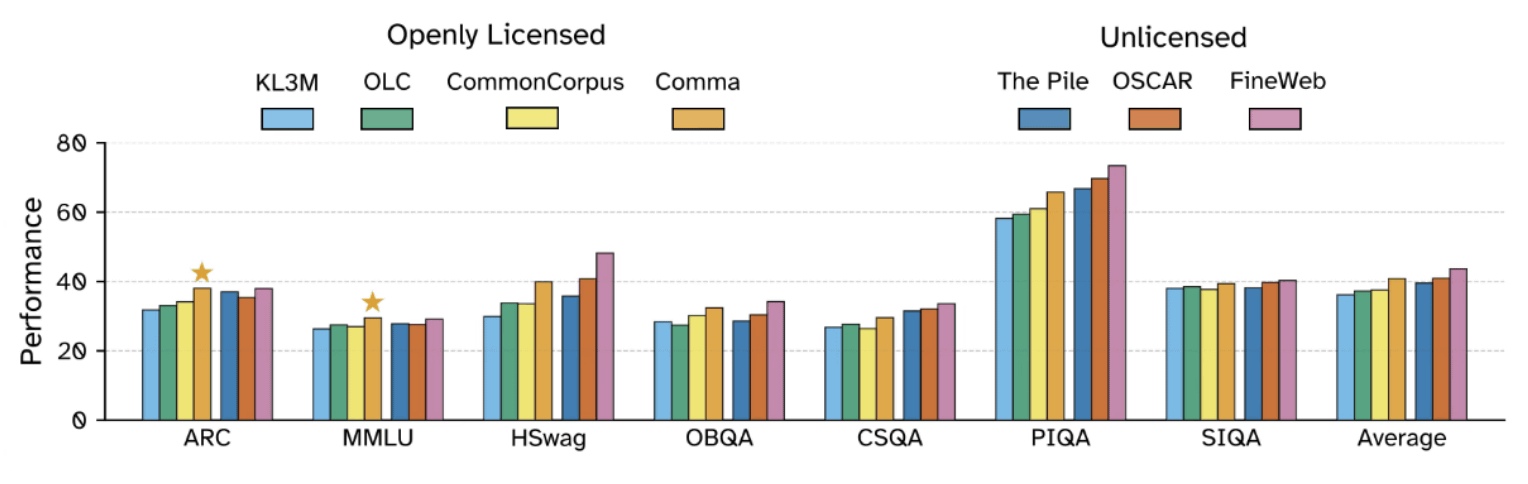
EleutherAIは「Common Pileで学習したモデルは、The PileやOSCARといったライセンスのないデータセットで学習したモデルと遜色ない性能でした。ただし、非常に大規模なデータプールから高品質なデータのみを厳しくフィルタリングしているFineWebには及びません」と報告しました。
EleutherAIは「このデータセットを『Common Pile v0.1』と呼ぶことは、非常に明確な意図表明です。私たちはこのリリースを大変嬉しく思っていますが、これは最後のステップではなく、最初のステップだと考えています。より大きく、より優れたバージョンを構築し、現在利用できないオープンライセンスのデータを解放し、より多くのものを一般に還元したいと考えています」と述べました。
・関連記事
ついにAI学習のためのデータが枯渇へ、データセットが不足しているAI企業は大規模で汎用的なLLMから小規模で専門性の高いモデルへの移行を余儀なくされる可能性大 - GIGAZINE
Metaが1億件以上の分子構造データを含む大規模量子化学データセット「OMol25」とAIモデル「Universal Model for Atoms(UMA)」をリリース - GIGAZINE
Stable Diffusionにも使われるデータセット「LAION-5B」に児童性的虐待コンテンツが見つかり開発元がリンクを削除した「Re-LAION-5B」をリリース - GIGAZINE
1兆のテキストトークン・34億個の画像・PDF・ArXivの論文などを含むオープンソースのデータセット「MINT-1T」をSalesforceが公開 - GIGAZINE
Metaの基礎AI研究チームが複数の研究を発表、AIモデルやデータセットなど複数の成果を共有 - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, Posted by log1i_yk
You can read the machine translated English article AI research institute EleutherAI release….