




LLMの仕組みとは?

ChatGPTやGeminiなど、ユーザーが気軽に使えるチャットボットはすべて「LLM(大規模言語モデル)」という技術に基づいて構築されています。とても滑らかで自然な文章を生成することができるLLMが実際にはどのように動いているのかについて、アニメーションを用いて難解なトピックをわかりやすく解説するYouTubeチャンネル「3Blue1Brown」が動画にしています。
Large Language Models explained briefly - YouTube


3Blue1Brownは、「大規模言語モデルとは、どんな文章に対しても次に来る単語を予測する洗練された数学的な関数である」と説明しています。
例えば、人とAIアシスタントが登場する短い映画の脚本があったとします。脚本には人がAIに質問しているところは書かれていますが、AIの回答部分がありません。

この脚本と、「どんな文章でも次に来る単語を正確に予測できる魔法のような機械」を組み合わせたとします。すると、脚本を機械に入力することで「AIの回答部分」を予測できます。予測は最初の1単語から始まり、何度も何度も繰り返すことで回答全体を予測できます。ChatGPTなどと対話するときはまさにこのことが起こっています。
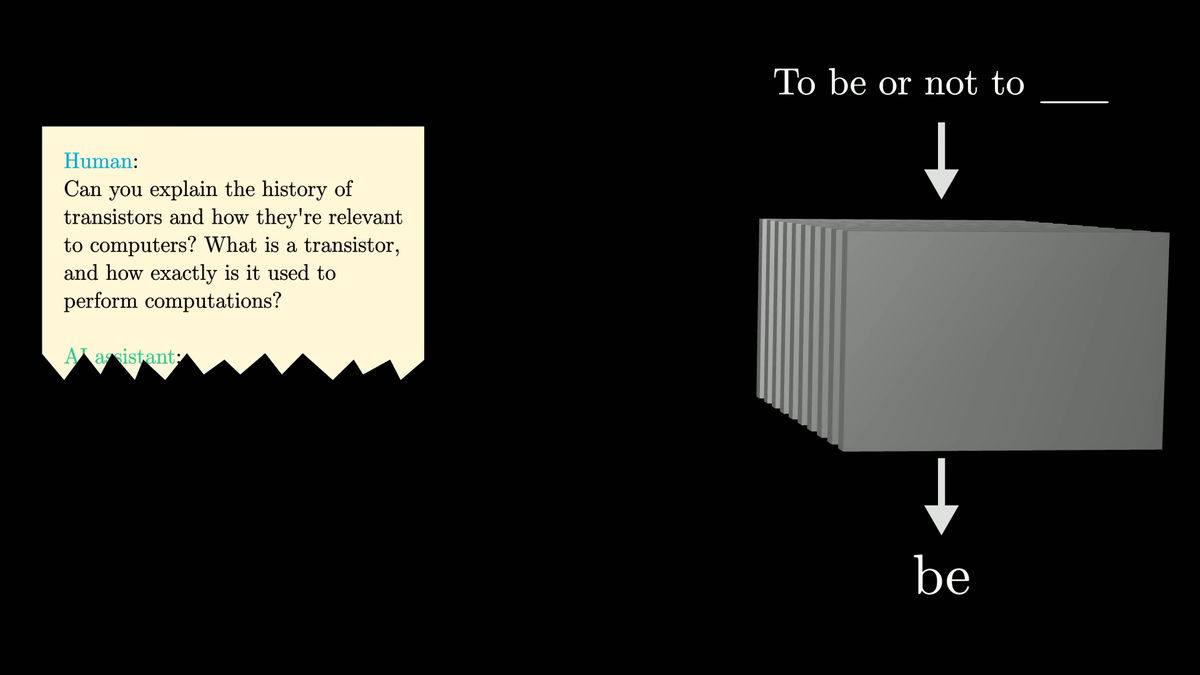
チャットボットでは、まずユーザーと架空のAIアシスタントのやり取りを示す文章が用意され、ユーザーが入力した内容が付け加えられています。架空のAIアシスタントが応答として言いそうな次の単語をモデルに繰り返し予測させ、そうして生成された文章がユーザーにまとめて表示されるという形です。

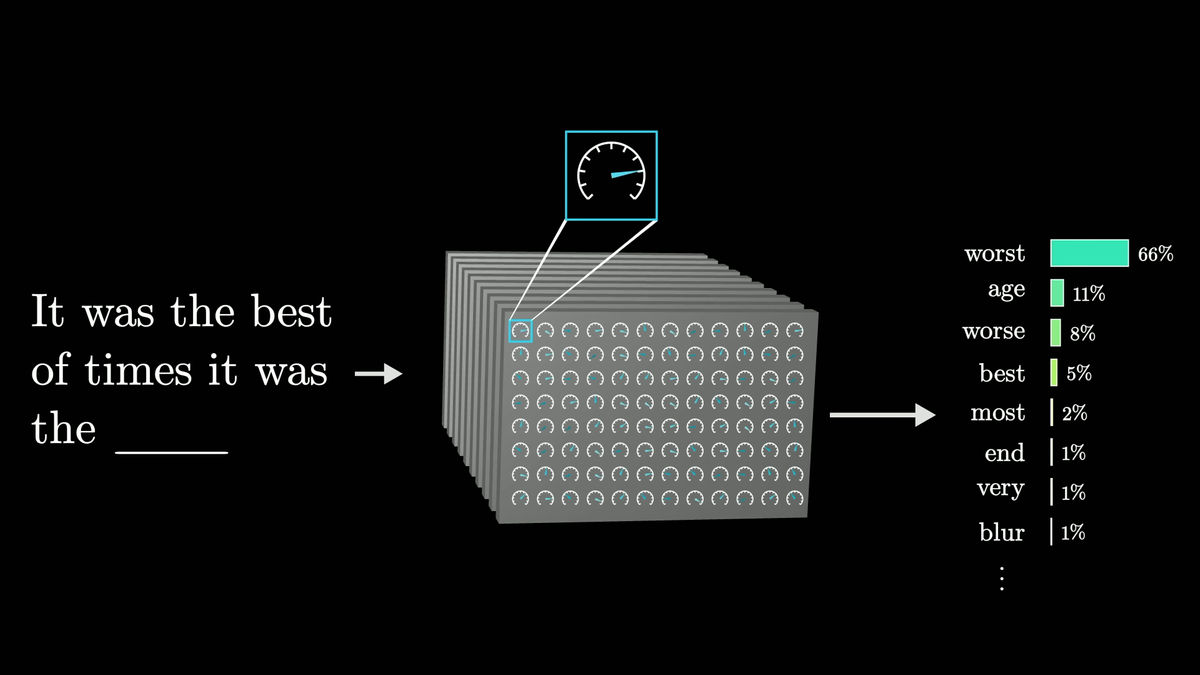
大規模言語モデルは次に来る1単語を正確に予測するのではなく、次に来る可能性のあるすべての単語を列挙し、それぞれに確率を割り当てています。生成の過程で確率の高い単語だけを選んでいれば間違いは少なくなりますが、確率の低い単語もランダムに選ばせるようにすると出力が自然に見える傾向があります。同じプロンプトでも実行するたびに異なる答えが得られるのはこのためです。

大規模言語モデルは基本的にインターネットから収集された膨大な量の文章を処理することによってこうした予測を行う方法を学習します。OpenAIのLLM「GPT-3」の学習に使われた文章量を標準的な人間が読むとしたら、24時間読み続けても2600年以上かかるはずです。さらに、GPT-3より新しいLLMはずっと多くのデータで学習されています。

学習は大きな機械のダイヤルを調整するようなものだと考えることができます。大規模言語モデルには「重み」というパラメーターがあり、このパラメーターを変更すると特定の入力に対する出力の確率が変わります。大規模言語モデルの「大規模」というのはこれらのパラメーターが数千億個もあるということです。人間が意図的にこれらのパラメーターを設定することはなく、モデルが入出力を繰り返すことで洗練されていきます。
学習は、文章中の最後の単語を除いたものをモデルに入力し、モデルが行った予測を実際の答えと比較することで行われます。誤差を小さくする調整を行い、モデルが予測した単語の中から正解を選択する可能性を少し高め、他の単語を選択する可能性を少し低くするようにします。これを何兆もの文章に対して行うと、モデルは学習データに対して正確な予測をするようになるだけでなく、見たことのない文章に対しても妥当な予測を行うようになります。

学習には膨大な数のパラメーターと学習データによる計算が必要で、この計算の多くは複数の演算を並列処理できるGPUが行っています。2017年、Googleの研究者チームがTransformerという学習モデルを発表したことで、並列処理の基礎ができあがりました。Transformerは文章を最初から最後まで読むのではなく、一度に並行してすべてを取り込むのが特徴です。文章中で次に続く単語を正確に予測するために必要なあらゆる情報を符合化することで計算を高速化し、学習の時間を圧倒的に縮小できます。

しかし、これだけではチャットボットとして使うことはできません。インターネット上のランダムな文章の続きを予測することができたとしても、優秀なAIアシスタントになったわけではないからです。大規模言語モデルに基づいたチャットボットを構築するには、ここまでのプロセスである「事前学習」に加え、人間からのフィードバックによる「強化学習」が必要になります。

人間のフィードバックによる強化学習では、役に立たないまたは問題のある予測に人の手でフラグを立てます。その修正によってモデルのパラメーターがさらに変更され、ユーザーが好む予測をするようになります。

3Blue1Brownは「モデルの出力は学習の際のパラメーターの調整によって決まるので、モデルがなぜ特定の予測を行うのかを判断するのは非常に難しいです。確かにわかることは、大規模言語モデルが生成する言葉は不気味なほど滑らかで魅力的で、さらには役に立つということです」とまとめました。
・関連記事
畳み込みニューラルネットワークの処理についてアニメーションで解説する「Animated AI」 - GIGAZINE
大規模言語モデルの仕組みが目で見てわかる「Transformer Explainer」 - GIGAZINE
ChatGPTにも使われる機械学習モデル「Transformer」が自然な文章を生成する仕組みとは? - GIGAZINE
画像生成AIのためのプロンプト・呪文が実際にはどのようなトークンとして伝わっているかを見せてくれる「Tokenizer」 - GIGAZINE
Googleが「大規模言語モデルに視覚を与える仕組み」について解説、メルカリと協力して作成したデモも公開 - GIGAZINE
・関連コンテンツ








in 動画, ソフトウェア, Posted by log1p_kr
You can read the machine translated English article How does an LLM work?….