




AMDがAMD製GPUでトレーニングしたオープンソースの言語モデル「Instella」をリリース、同等モデルより高性能

AMDがオープンソースの言語モデル「Instella」を発表しました。InstellaはAMD Instinct MI300X GPUを使用してトレーニングされた30億パラメーターのモデルで、Llama-3.2-3B、Gemma-2-2B、Qwen-2.5-3Bなどの最先端のオープンウェイトモデルと比較して競争力のあるパフォーマンスを発揮すると述べられています。
Introducing Instella: New State-of-the-art Fully Open 3B Language Models — ROCm Blogs
https://rocm.blogs.amd.com/artificial-intelligence/introducing-instella-3B/README.html

Instellaは30億パラメーターを持つテキスト専用のトランスフォーマーベースの言語モデルで、36個のデコーダーレイヤーを持ち、それぞれのデコーダーレイヤーに32個のアテンションヘッドがあります。最大4096トークンのシーケンスに対応し、語彙サイズは約5万トークンとのこと。
Instellaは128個のAMD Instinct MI300X GPUを使用して4兆1500億トークンのデータでトレーニングされています。トレーニングに使用されたトークン数と性能のバランス面で既存の完全オープンなモデルを上回ったほか、最先端のオープンウェイトモデルと比較しても引けを取らない性能を発揮したとのこと。
下図は縦軸をベンチマークの平均スコア、横軸をトレーニングに使用したトークン数としてInstellaとLlama-3.2-3B、Gemma-2-2B、Qwen-2.5-3Bなどの最先端のオープンウェイトモデルを並べたもの。左の事前トレーニング済みモデル同士の比較ではInstellaが既存のモデルを上回り、右の命令調整済みモデル同士の比較でもInstellaは互角以上のポジションについています。
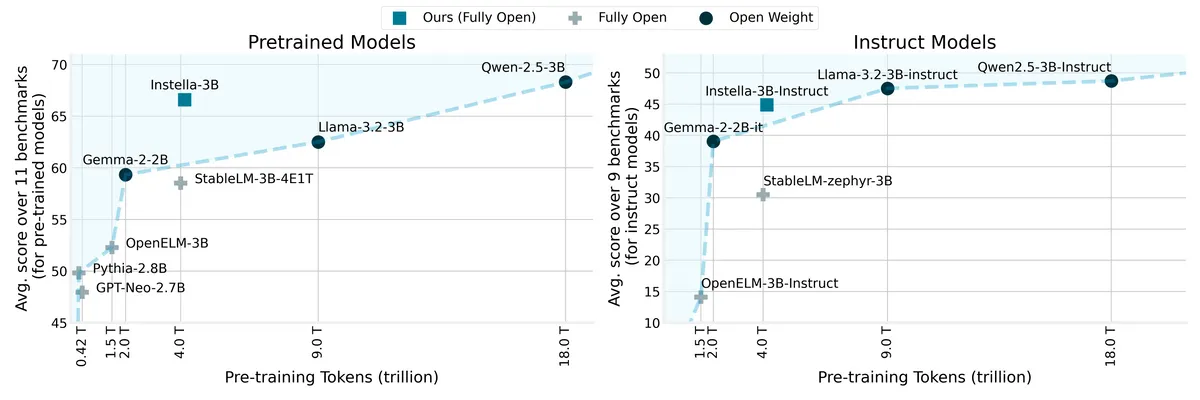
命令調整済みモデルの具体的なベンチマークの結果は以下の通り。各ベンチマークにおいて最も優れている数字が太字で、2番目に優れている数字に下線が引いてあります。
| Models | Size | Training Tokens | Avg | MMLU | TruthfulQA | BBH | GPQA | GSM8K | Minerva MATH | IFEval | AlpacaEval 2 | MT-Bench |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Open Weight Models | ||||||||||||
| Gemma-2-2B-Instruct | 2.61B | ~2T | 39.04 | 58.35 | 55.76 | 42.96 | 25.22 | 53.45 | 22.48 | 55.64 | 29.41 | 8.07 |
| Llama-3.2-3B-Instruct | 3.21B | ~9T | 47.53 | 61.50 | 50.23 | 61.50 | 29.69 | 77.03 | 46.00 | 75.42 | 19.31 | 7.13 |
| Qwen2.5-3B-Instruct | 3.09B | ~18T | 48.72 | 66.90 | 57.16 | 57.29 | 28.13 | 75.97 | 60.42 | 62.48 | 22.12 | 8.00 |
| Fully Open Models | ||||||||||||
| StableLM-zephyr-3B | 2.8B | 4T | 30.50 | 45.10 | 47.90 | 39.32 | 25.67 | 58.38 | 10.38 | 34.20 | 7.51 | 6.04 |
| OpenELM-3B-Instruct | 3.04B | ~1.5T | 14.11 | 27.36 | 38.08 | 24.24 | 18.08 | 1.59 | 0.38 | 16.08 | 0.21 | 1.00 |
| Instella-3B-SFT | 3.11B | ~4T | 42.05 | 58.76 | 52.49 | 46.00 | 28.13 | 71.72 | 40.50 | 66.17 | 7.58 | 7.07 |
| Instella-3B-Instruct | 3.11B | ~4T | 44.87 | 58.90 | 55.47 | 46.75 | 30.13 | 73.92 | 42.46 | 71.35 | 17.59 | 7.23 |
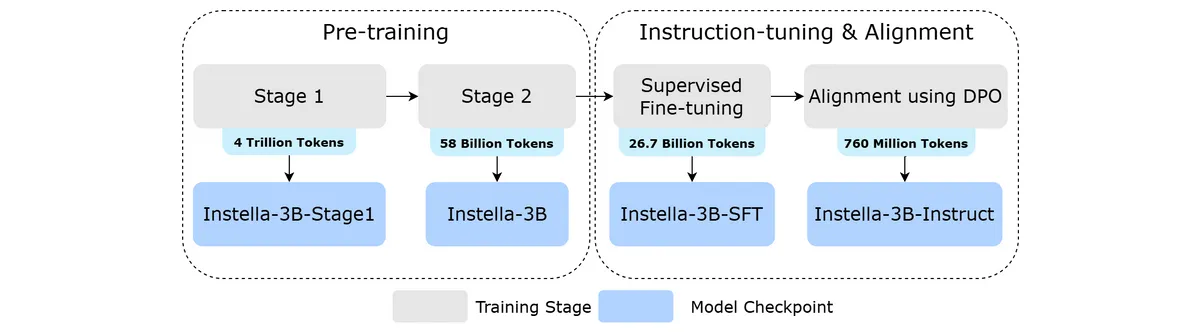
トレーニングパイプラインは以下の通り。まず4兆トークンのデータで1段階目の事前トレーニングを行い、続いて580億トークンのデータで多段階の推論や数学の能力を強化する2段階目の事前トレーニングを行ったそう。その後、267億トークンの指示応答ペアデータでユーザーのクエリに応答する能力を高め、最後に7億6000万トークンのデータで出力の有用性、正確性、安全性を高めるためのトレーニングを行いました。
Instellaは「完全にオープンでアクセス可能なモデル」として、トレーニングのハイパーパラメータやデータセット、使用したコードなどが公開されています。トレーニングの各段階のチェックポイントもそれぞれHugging Faceからダウンロード可能です。
AMDはInstellaの取り組みを通して、「AMD製のGPU上で言語モデルをトレーニングする可能性を示せた」とコメントしました。今後もコンテキストの長さ、推論能力、マルチモーダル機能など複数の側面からモデルを強化していく予定とのことです。
・関連記事
AIのトレーニングで使用されるチップ「H100」「H200」「MI300X」の性能を比較した結果判明した事実とは? - GIGAZINE
Intelの身売りはAMDとの「クロスライセンス契約」により阻止される可能性が高いとの指摘 - GIGAZINE
AMDのリサ・スーCEOが「NVIDIAのCEOとの関係」や「CEOに任命された経緯」などを語る - GIGAZINE
AMDがRDNA 4採用グラボ「Radeon RX 9070 XT」と「Radeon RX 9070」を発表、RX 9070 XTはNVIDIAのRTX 5070 Tiより2万円安くて同等性能でレイトレ性能は前世代の2倍 - GIGAZINE
完全にオープンで再現可能な大規模言語モデル「OpenCoder」がリリースされる - GIGAZINE
・関連コンテンツ








in ソフトウェア, Posted by log1d_ts
You can read the machine translated English article AMD releases Instella, an open source la….