Cohere releases 'Command A+', a multimodal AI built for agent tasks, a high-performance open-source model for enterprises that can be deployed in their own environments.

Cohere has open-sourced Command A+ , which it claims is the fastest and most powerful in its Command series of language models. Command A+ is an enterprise-grade model that handles complex inference, multimodal processing, multilingual support, and AI agent-like tasks, and runs on a minimum configuration of two NVIDIA H100s or one Blackwell-generation B200.
Introducing Command A+ | Cohere
CohereLabs/command-a-plus-05-2026-w4a4 · Hugging Face
https://huggingface.co/CohereLabs/command-a-plus-05-2026-w4a4
Command A+ is a model developed based on Cohere's one year of experience deploying its enterprise AI workspace, 'North,' to customers. Cohere positions this model as the foundation for enabling ' sovereign AI ' that companies can run, manage, and adapt within their own environments.
Command A+ is also a model that integrates the functions of the conventional ' Command A ' series into one. While Command A Reasoning focused on inference, Command A Vision on multimodal processing, and Command A Translate on multilingual processing, Command A+ handles inference, multimodal processing, tool usage, and support for 48 languages all in one model.

The model name is 'command-a-plus-05-2026' and it is developed under the Apache 2.0 license. The architecture is '
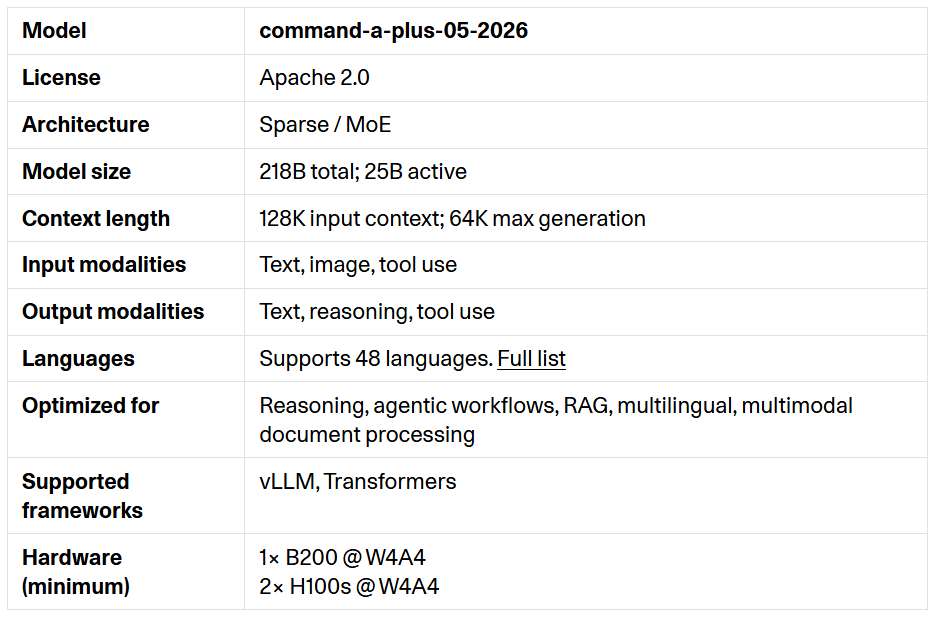
Output supports text, inference, and tool usage, and multilingual support has expanded from 23 languages to 48. Command A+ employs a new tokenizer, reducing the number of tokens required to generate the same response, with improvements in token efficiency particularly noticeable in Arabic (20%), Korean (16%), and Japanese (18%).
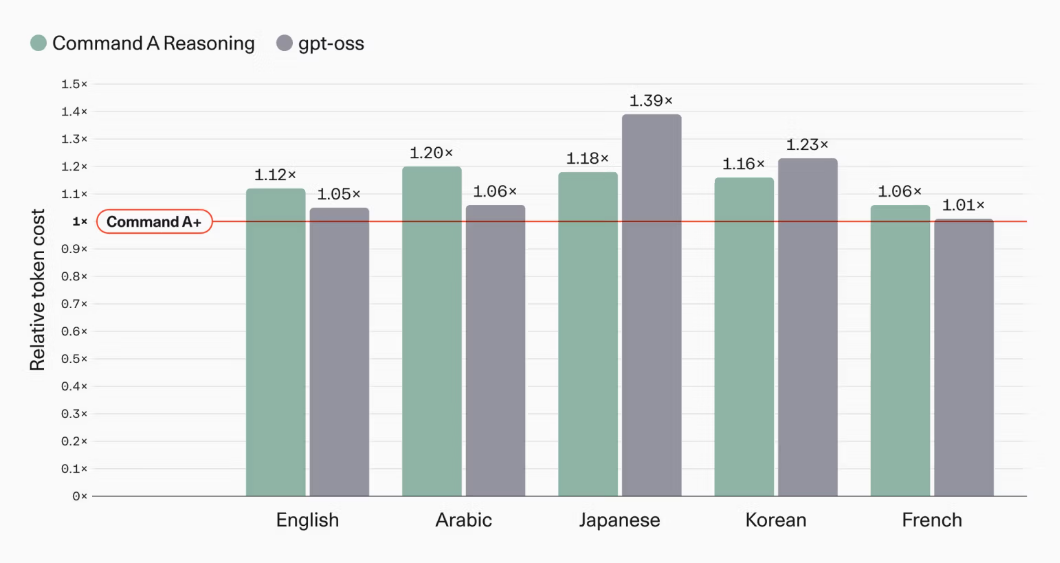
Command A+ is a model developed by Cohere and Cohere Labs, optimized for agent processing, multilingual processing, heavy inference tasks, and visual information processing including image input. The publicly available model includes quantization versions of BF16, FP8, and W4A4, and can be tried out at Hugging Face Space.
The minimum GPU requirements for each quantization are four
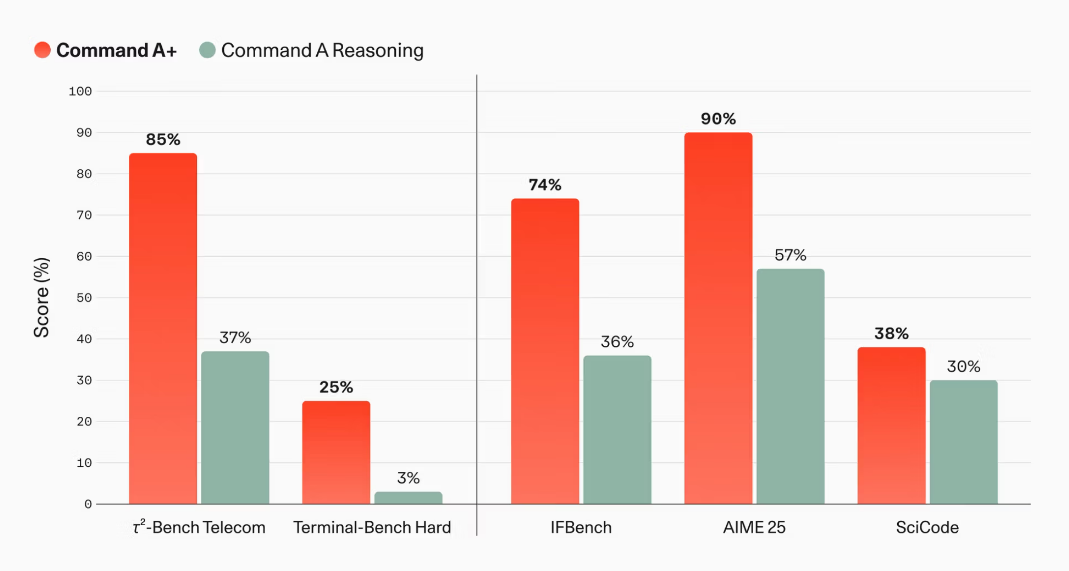
In terms of performance, significant improvements have been observed compared to Command A Reasoning. τ 2 -Bench Telecom improved from 37% to 85%, Terminal-Bench Hard from 3% to 25%, IFBench from 36% to 74%, AIME 25 from 57% to 90%, and SciCode from 30% to 38%.
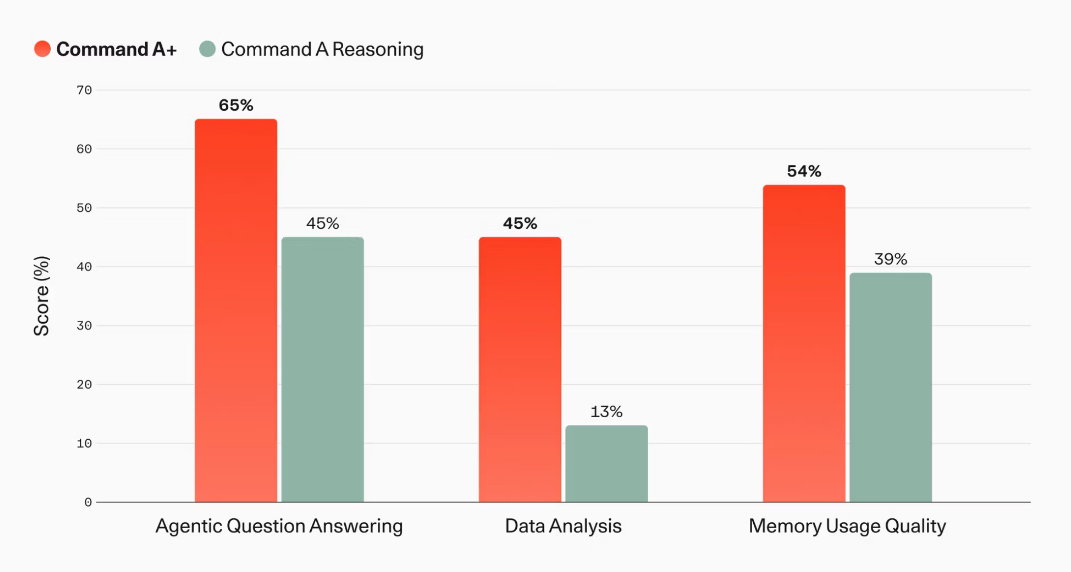
Internal evaluations for North also showed that Command A+ demonstrated improvements in processing intended for enterprise use. Agent Question Answering improved from 45% to 65%, Data Analysis from 13% to 45%, and Memory Usage Quality from 39% to 54%, indicating improved performance in agent processing that uses memory for cloud file systems, spreadsheets, and past sessions.
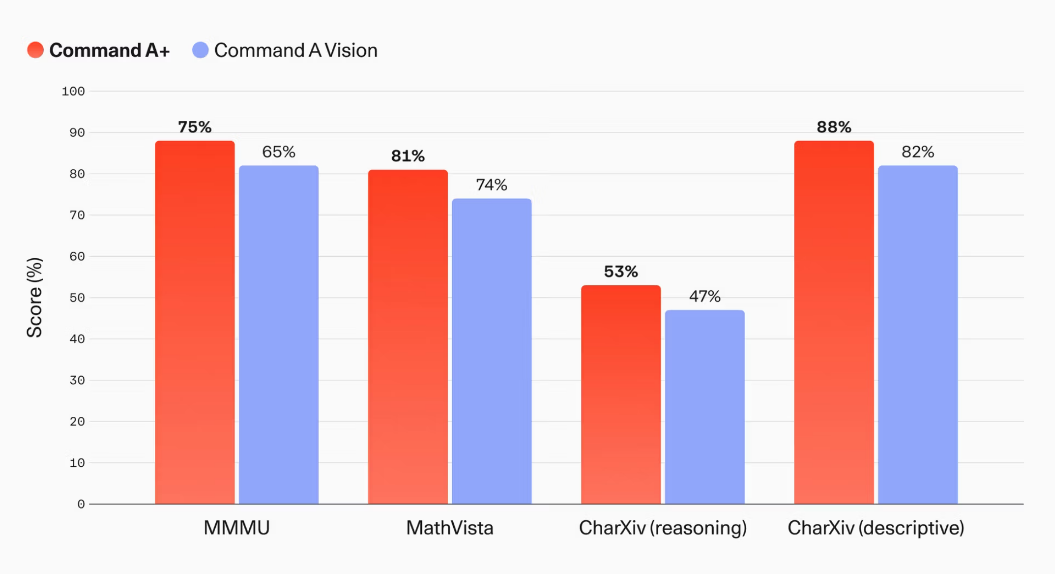
The following are the results of a comparison of multimodal performance between Command A+ and Command A Vision. Command A+ achieved 63% on
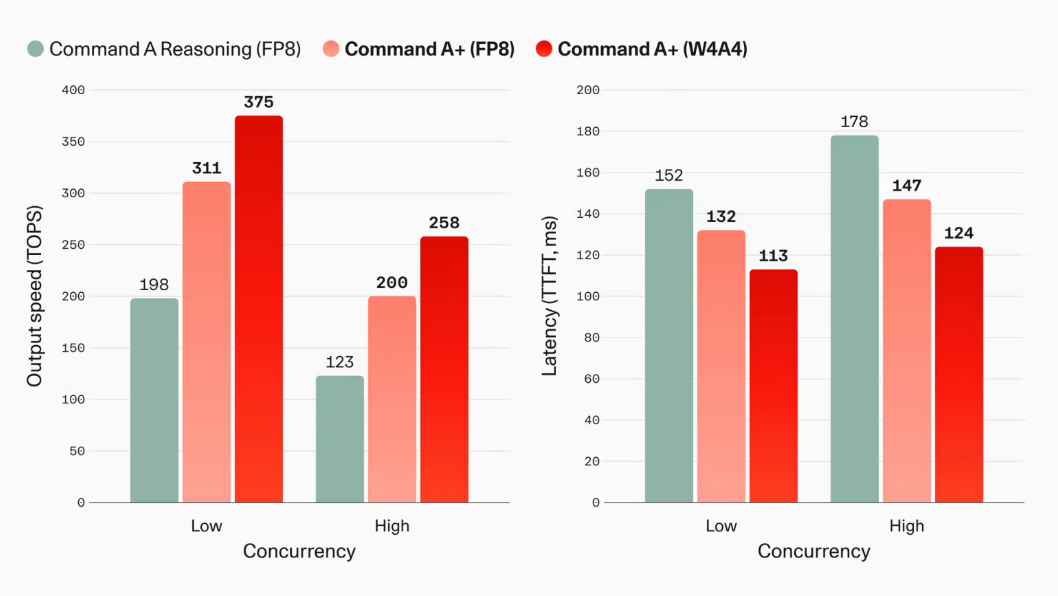
Efficiency is another major feature of Command A+. Cohere claims that compared to Command A Reasoning under the same quantization and parallel execution conditions, the output tokens per second (TFT) is improved by up to 63%, and the time to return the first token (TTFT) is reduced by up to 17%.
W4A4 quantization is said to provide a further 47% speed improvement and a 13% latency reduction. In addition, speculative decoding optimized for the MoE architecture enables 1.5 to 1.6 times faster inference for both text and multimodal inputs.
According to Cohere, the W4A4 quantized version applies NVFP4 W4A4 quantization, using 4-bit weights and activations only to the expert portion of MoE, while maintaining full precision for QKV, output projection, KV cache, and attention calculations. Furthermore, to minimize quality degradation after quantization, it uses Quantization Aware Distillation , which brings the quantized model closer to the output distribution of the full-precision model.
Cohere also shared comments from Vivek Mahajan, CTO of System Platforms at Fujitsu, with whom they are partnering in their AI business. Mahajan stated, 'Command A+'s MoE architecture and agent performance align with Fujitsu and Cohere's jointly developed enterprise LLM ' Takane ' and Fujitsu's AI platform ' Fujitsu Kozuchi Enterprise AI Factory ' in providing sovereign AI solutions.'
Command A+ can obtain model parameters via Hugging Face and can also be deployed to an inference environment managed by Model Vault. For a free trial, you can use Hugging Face Space or a Cohere API key, and it supports vLLM and Transformers. However, running the W4A4 version with vLLM requires vLLM 0.21.0 or later, and accurate response parsing requires the Cohere melody library.
Related Posts:








in AI, Posted by log1i_yk