Interfaze, an AI model specializing in routine tasks such as OCR, voice recognition, and structured output, has been released.

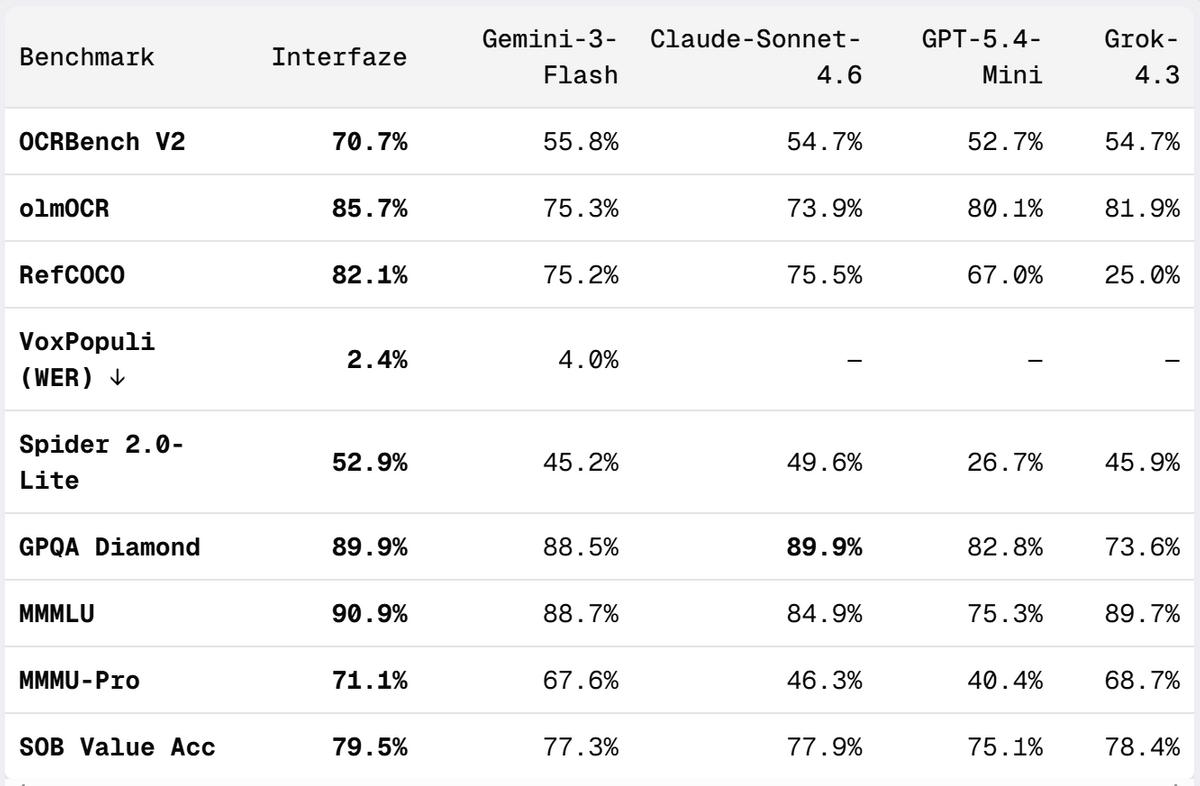
AI company Interfaze has unveiled a new AI model architecture called 'Interfaze,' which aims to process 'tasks with predetermined answers,' such as OCR, speech recognition, and structured data output, with higher accuracy and lower cost than large-scale language models. According to their official blog, Interfaze demonstrated superior performance in nine benchmarks, including OCR, image recognition, speech recognition, and JSON output, compared to lightweight and high-speed models such as Gemini-3-Flash, Claude-Sonnet-4.6, GPT-5.4-Mini, and Grok-4.3.
Interfaze: A new model architecture built for high accuracy at scale - Interfaze

Humans are good at reading documents, understanding their meaning, and picking up on ambiguous instructions, but they are not suited to tasks like reading a 50-page PDF character by character, recording the coordinates of each word, and then translating it into another language. It would be time-consuming, prone to errors, and costly.
According to an article in Interfaze, currently widely used Transformer-based large-scale language models also possess similar properties. In other words, while they excel at contextual understanding and creative processing, they are prone to human-like errors in tasks requiring accuracy and reproducibility, such as OCR and data extraction.
Interfaze employs a hybrid configuration that combines task-specific neural networks such as DNNs and CNNs with a Transformer decoder. DNNs and CNNs are easily optimized for specific tasks such as OCR, translation, and GUI detection, and can also output metadata such as character position information and confidence scores. On the other hand, they are not good at flexible inference or linguistic judgment on their own. Interfaze aims to achieve both the accuracy of standardized tasks and the flexibility of LLMs by compensating for this weakness with Transformers.
The diagram below illustrates the flow of how Interfaze processes input and generates output. Prompts undergo preprocessing before being sent to the core component, which combines DNNs or CNNs with Transformers, and interacts with task-specific adapters such as OCR, object detection, translation, and speech recognition. Subsequently, only the necessary information is organized and output as text or JSON through decoders and structured output models, demonstrating that Interfaze is designed to combine the 'accuracy of specialized models' with the 'flexibility of Transformers.'
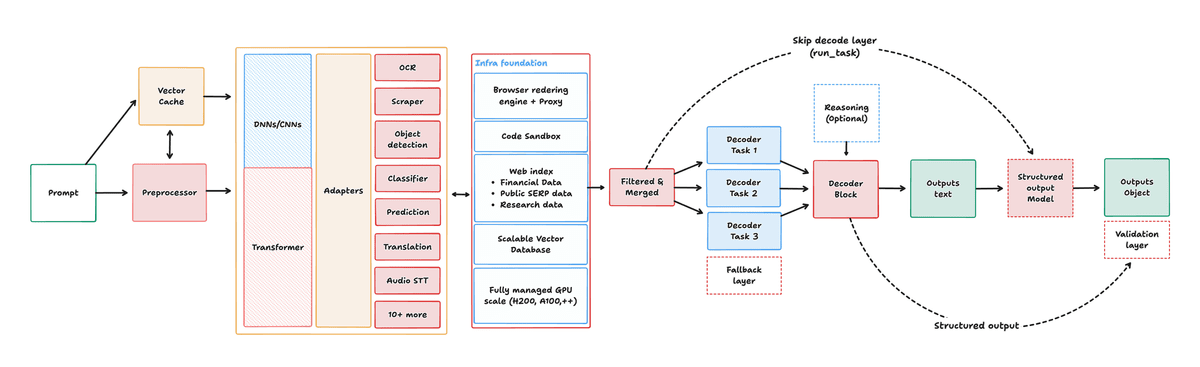
The key point is that Interfaze is not designed as a 'universal AI that replaces LLMs,' but rather as an 'AI specialized in routine tasks that developers process in large quantities, such as OCR, speech recognition, and structured output.' The article explains that while high-performance general-purpose models like Claude Opus and GPT-5.5 are powerful for coding and complex inference, they are impractical for high-volume processing like OCR and translation due to cost and speed considerations.
Interfaze's specifications include a context window of 1 million tokens, a maximum output of 32,000 tokens, and support for text, images, audio, and files as input. An inference function is also available, but it is disabled by default. The price is similar to that of Gemini-3-Flash, at $1.50 (approximately 236 yen) per 1 million input tokens and $3.50 (approximately 552 yen) per 1 million output tokens.
Interfaze's primary focus is on OCR (Optical Character Recognition). Its selling point is its ability to handle not only text but also the position of diagrams and graphics simultaneously, even with long PDFs, documents with complex layouts, and images. For example, if you input a multi-column page like those in a magazine, it can extract the text on the page while also returning the coordinates of illustrations and diagrams in JSON format.
The graph below compares the OCR accuracy of various software programs for long, complexly laid PDFs. Interfaze achieved the highest accuracy at 85.7%, outperforming Chandra OCR, olmOCR, Grok-4.3, and GPT-5.4-Mini.
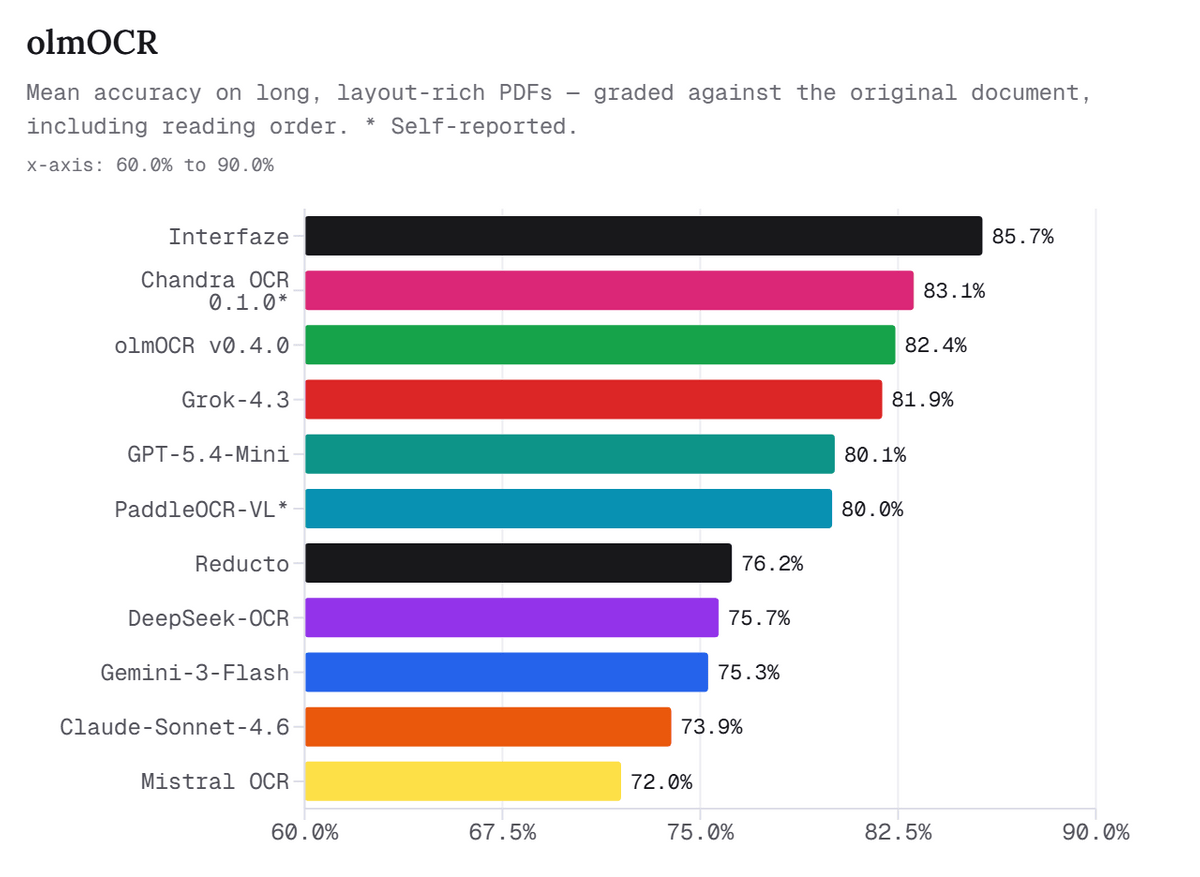
The article states that Interfaze's strength in OCR lies not only in its ability to read text well using a CNN encoder, but also in its ability to combine image and graphic detection, translation layers, and semantic understanding using a Transformer within the same vector space.
Another important topic is structured output. Many LLMs are good at outputting in a format that conforms to the JSON schema, but the values included in it are not always correct. For example, even if it can return fields such as 'Name,' 'Address,' 'Date,' and 'Amount' in a clean JSON format, it is unusable in practice if the values themselves are incorrect.
Interfaze has released the Structured Output Benchmark (SOB) to measure this problem. SOB measures whether a model can correctly output correct information as JSON when given the correct information as context. The evaluation targets include text, images, and audio, and the accuracy is ultimately measured by whether the last value of the JSON exactly matches the correct answer.
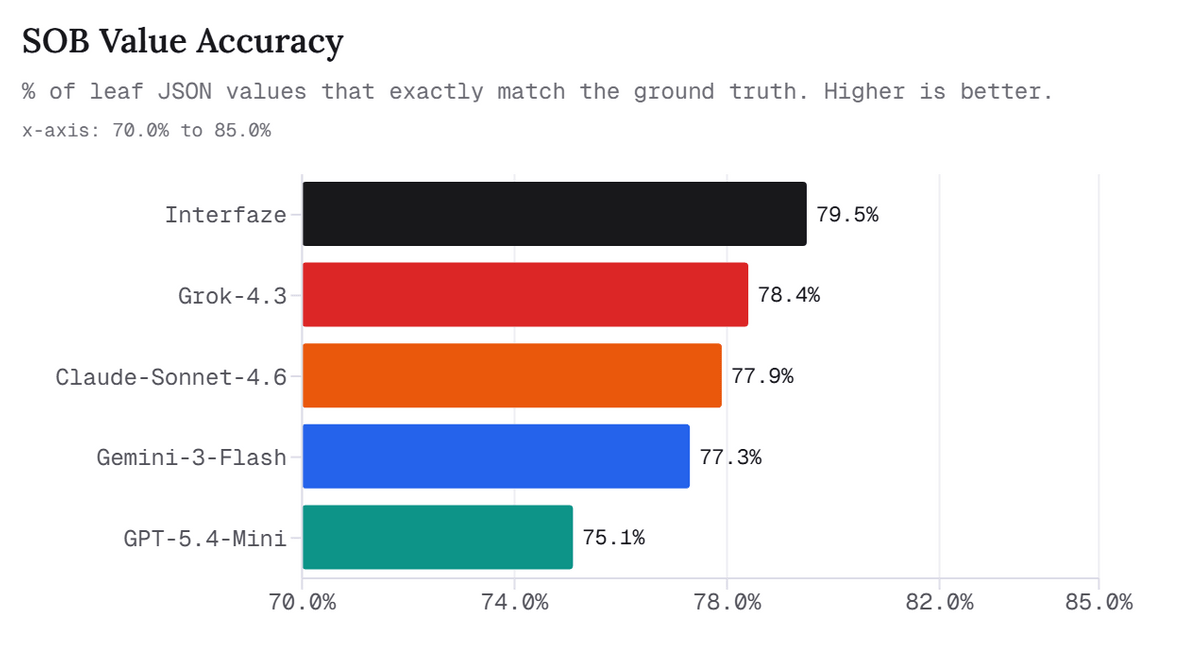
The graph below shows SOB Value Accuracy, which indicates the percentage of JSON values that perfectly matched the correct answer. Interfaze is at the top with 79.5%, slightly ahead of Grok-4.3, Claude-Sonnet-4.6, Gemini-3-Flash, and GPT-5.4-Mini.
Interfaze also scores highly in multilingual performance. MMMLU is a benchmark that measures knowledge and comprehension in multiple languages, and it is an indicator of how stably it can handle processing in languages other than English.
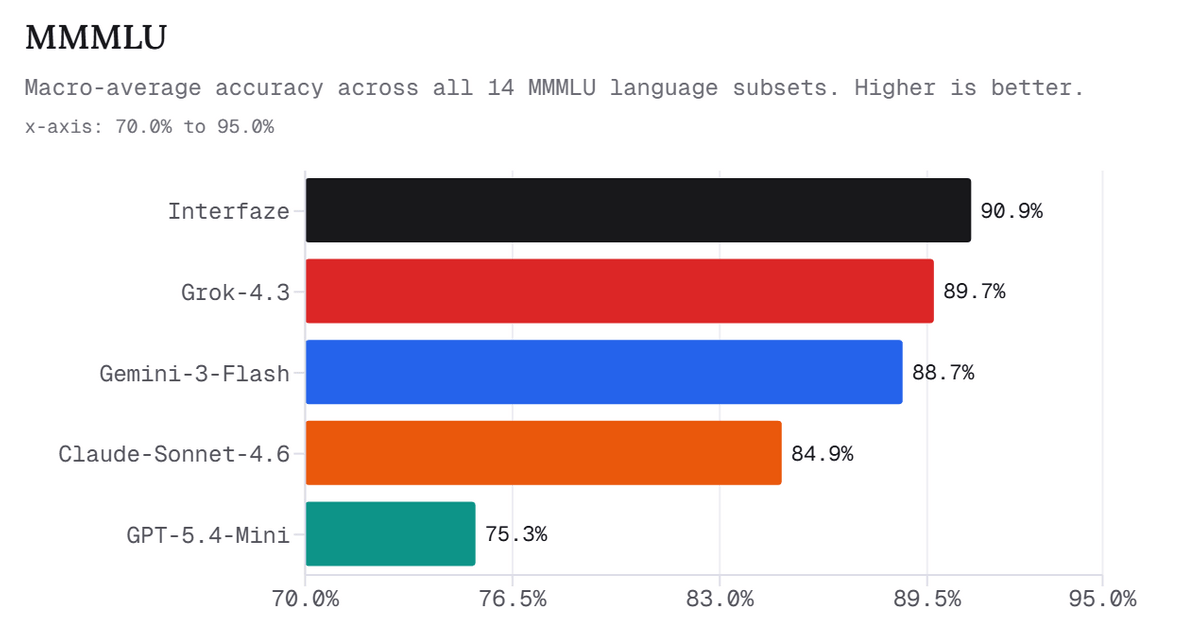
The graph below shows the macro-average precision in a subset of 14 languages using MMMLU. Interfaze achieves 90.9%, surpassing Grok-4.3's 89.7% and Gemini-3-Flash's 88.7%.
In transcription, Interfaze demonstrates performance close to that of professional speech recognition services. VoxPopuli-Cleaned-AA is a speech recognition benchmark based on multilingual speeches from the European Parliament, and is evaluated by word error rate (WER).
The graph below compares the WER (Write Error Rate) in VoxPopuli-Cleaned-AA. The lowest is Scribe v2 at 1.7%, and Interfaze is second at 2.4%, but it can be seen that it has a lower error rate than Deepgram Nova-3, Whisper Large v3, and Gemini-3-Flash.
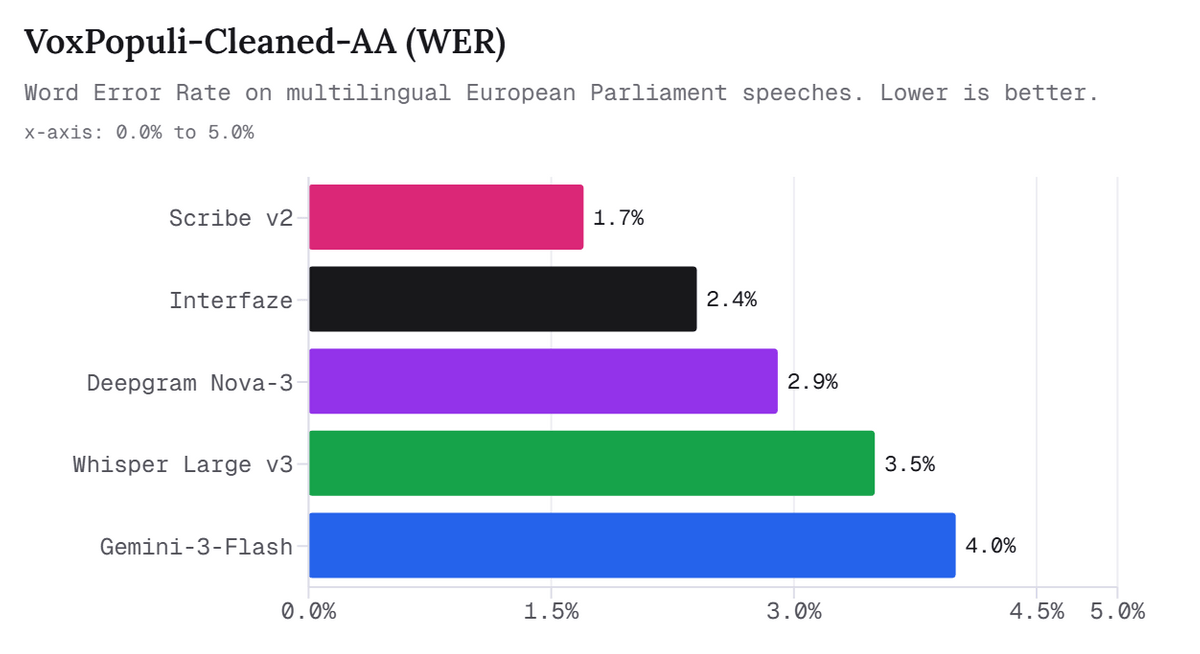
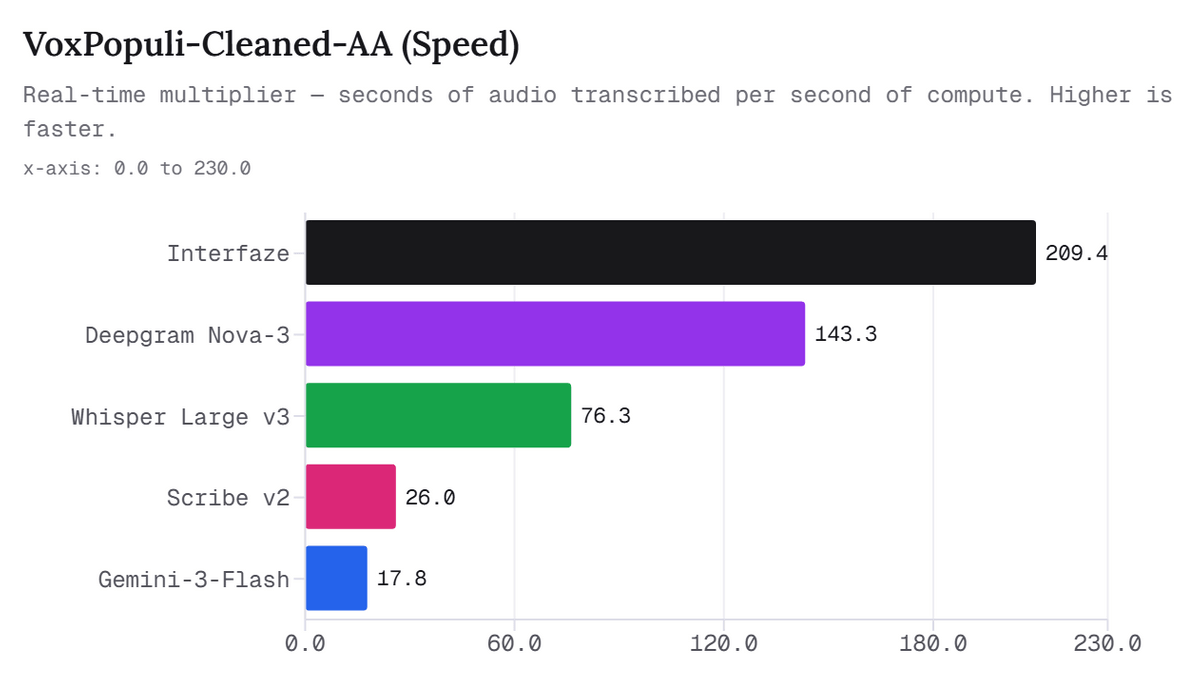
Furthermore, Interfaze also boasts strengths in speech recognition speed. According to the article, Interfaze can process 209 seconds of audio in 1 second of computation time. This is approximately 1.5 times faster than Deepgram Nova-3, approximately 8 times faster than Scribe v2, and more than 11 times faster than Gemini-3-Flash.
The image below shows a comparison of transcription speeds in VoxPopuli-Cleaned-AA. Interfaze comes out on top with a speed of 209.4, significantly outperforming Deepgram Nova-3's 143.3 and Whisper Large v3's 76.3.
The benchmarks for the entire article compare nine items: OCRBench V2, olmOCR, RefCOCO, VoxPopuli, Spider 2.0-Lite, GPQA Diamond, MMMLU, MMMU-Pro, and SOB Value Accuracy. Interfaze ranked first or in the top ranks in many items, and showed particularly outstanding results in OCR, structured output, multilingual processing, and speech recognition speed.
Interfaze is available as an OpenAI-compatible Chat Completions API, and can be implemented simply by pointing the baseURL to the Interfaze API using existing OpenAI SDKs, Vercel AI SDKs, LangChain, etc.
Furthermore, a 'partial model activation' feature is available that activates only a part of the model each time, rather than running the entire model. For example, specifying an OCR task via the system prompt will run only the pure OCR processing, resulting in faster and lower-cost results. However, it is stated that only one task can be executed per request, and the output format will be fixed.
Interfaze incorporates web search, scraping, and code sandboxing, making it useful for supplementing personal information and extracting web data. Furthermore, an example is shown of transcribing a 1 hour and 35 minute podcast into approximately 50 seconds of text, returning it as timestamped chunks.
Interfaze explains that its model is not a 'giant AI that can do anything,' but rather a model that focuses on tasks that businesses and developers routinely process in large quantities, such as 'reading large amounts of documents,' 'high-speed transcription of speech,' and 'extracting accurate values from images and PDFs and converting them to JSON.' Rather than replacing the creativity and advanced reasoning that LLM excels at, it prioritizes processing routine tasks where errors are unacceptable quickly, cheaply, and accurately.
Interfaze emphasizes that it's important to combine the expertise of DNNs and CNNs with the flexibility of Transformers, depending on the application, rather than leaving all processing to general-purpose LLMs. The company stated that it will continue its research and improvements to make processing with predetermined answers more efficient and easier to handle.
Related Posts:





in AI, Posted by log1d_ts