OpenAI explains that the standard benchmark used to measure AI coding ability is 'no longer meaningful,' and that examining the problems that initially failed to solve revealed that the problems themselves were flawed.

'
Why SWE-bench Verified no longer measures Frontier's coding ability | OpenAI
https://openai.com/ja-JP/index/why-we-no-longer-evaluate-swe-bench-verified/
OpenAI's ' SWE-bench ,' released in 2023, uses resolved GitHub issues from one of 12 open-source Python repositories as sources and combines them with corresponding pull requests to provide tests to determine whether the code changes generated by the model are correct. The AI model is required to generate code fixes and changes based only on the original problem text and the state of the repository before the fix, and the tests are performed and evaluated after the changes are applied. Because it was found that SWE-bench systematically underestimated the autonomous software engineering capabilities of the model, SWE-bench Verified was released in 2024 as a benchmark that provides a more accurate evaluation.
Since its release, SWE-bench Verified has been widely used to evaluate state-of-the-art models. Initially, model performance improved rapidly, but from August 2025 to February 2026, the improvement slowed to about 6% over six months. There was a need to re-examine the validity of SWE-bench Verified to determine whether this slowdown indicated the limitations of the model or reflected the characteristics of the dataset itself.
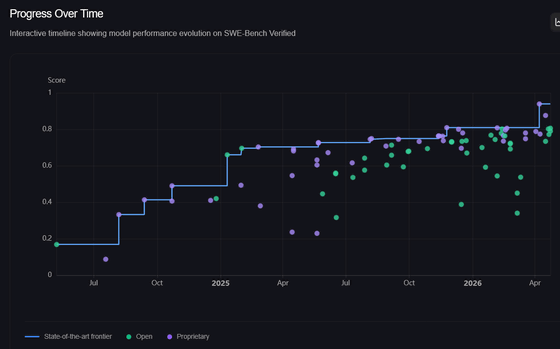
In February 2026, OpenAI reported that a detailed analysis revealed two significant problems with SWE-bench Verified.
The first problem is a flaw where 'tests sometimes reject correct solutions.' OpenAI's analysis audited 27.6% of the datasets that the model failed to solve and found that at least 59.4% contained 'flawed test cases that rejected the submission of functionally correct answers.' This means that even if the AI has made the correct code correction, it may be judged as 'incorrect' due to improper test design, such as the answer not being singular. OpenAI states, 'This is a phenomenon that occurred despite our best efforts to improve it during the initial creation of SWE-bench Verified.'

Another significant problem is 'data contamination.' The SWE-bench problems are taken from open-source repositories used by many model providers for training purposes. OpenAI's analysis found that in some cases, state-of-the-art models were able to reproduce the problem statements and actual corrected code, indicating that they were essentially 'looking at the questions and answers before the exam.' This means that improvements in benchmark performance are likely not due to improvements in the models themselves, but rather to 'how much the models referenced the benchmark during training.'
OpenAI has also presented verification results using its latest model, GPT-5.2 , as of February 2026. Human review of some of the problems judged as 'failures' in SWE-bench Verified revealed numerous cases where correct fixes had actually been made, but the results were incorrect due to flaws in the testing. Furthermore, examples were found where the model could directly reproduce the code changes included in the problem, suggesting the impact of data contamination due to pre-training.
In response to these issues, OpenAI has stopped reporting results for SWE-bench Verified and is recommending the use of new evaluation methods such as 'SWE-bench Pro' as an alternative. SWE-bench Pro employs a more rigorous evaluation design than before, including keeping some evaluation data confidential to prevent data contamination. While not perfect, the level of contamination is considerably lower than SWE-bench Verified, and none of the models were able to generate completely verbatim correct patches derived from pre-training. OpenAI also states that new approaches such as using uncontaminated datasets, evaluation methods that more closely resemble real-world environments, and evaluations that include human review will be important going forward.
Related Posts:








in AI, Posted by log1e_dh