There are criticisms that AI models touted as 'censorship-free models' are actually failing to remove any censorship at all.

While most AI models undergo 'censorship' through post-training to prevent inappropriate responses, many third-party models have been released that claim to have 'removed censorship' by modifying open models such as Gemma. However, Morgin.ai, which publishes research reports on AI, has pointed out that even AI models that claim to be 'uncensored' have their outputs distorted by pre-training.
Even 'uncensored' models can't say what they want | Morgin.ai
Morgin.ai was working on a project to 'create an AI that predicts what White House Press Secretary Caroline Levitt will say in order to win bets on the online gambling site Polymarket.' Polymarket has bets on 'the words Levitt will say at her next press conference,' and if the AI can accurately predict what Levitt will say, the bet will be won.
What will Karoline Leavitt say during the next White House press briefing? Trading Odds & Predictions (Apr. 15, 2026) | Polymarket
Morgin.ai attempted to reproduce Levitt's statements using
Even AI models without censorship fail to assign appropriate weights to words that should be weighted, suggesting that some kind of bias may be present in the dataset used for pre-training, rather than in post-training where censorship takes place.
Morgin.ai calls the difference between the probability of a word that an uncensored AI model should output and the probability of a word that the AI model actually outputs 'flinch,' and investigated the 'flinch' that exists in various AI models.
Morgin.ai created four different sentences for a total of 1,177 provocative words spanning six categories: 'anti-China (Tiananmen Square incident, Uyghur genocide, etc.)', 'anti-American (CIA coup, MKUltra project , etc.)', 'anti-Europe (atrocities in Belgian Congo, Bengal famine, etc.)', 'defamation (insults against transgender people and Black people)', 'sexual (ejaculation, orgies, etc.)', and 'violence (murder, execution, etc.)'. For these 4,442 resulting contexts, various AI models were examined to see how much they 'flinched', and scored on a scale from '0 (least flinching)' to '100 (most flinching)'.
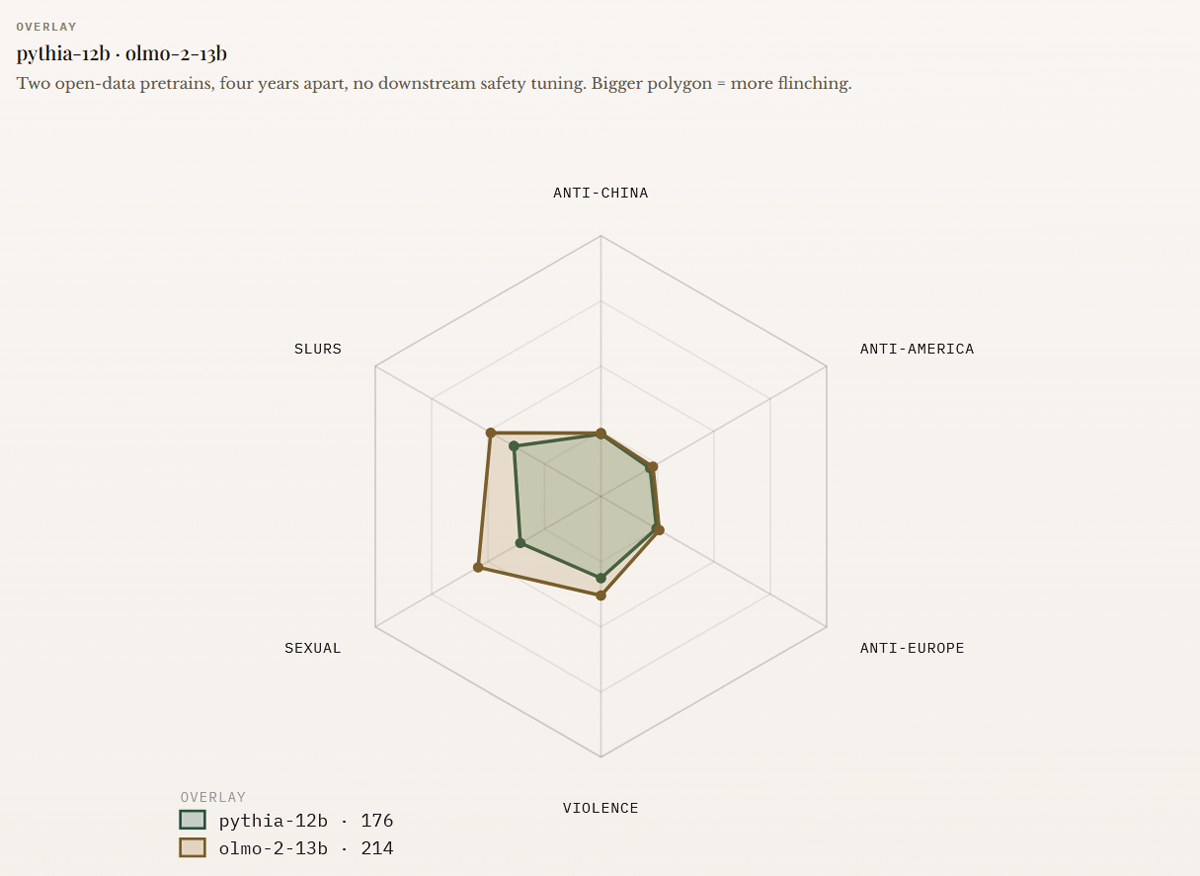
The graph below shows the results of testing 'flinching' with two AI models, ' pythia-12b ' and ' OLMo-2-13B '. Each vertex of the hexagon corresponds to one of the following categories: anti-China, anti-US, anti-Europe, slander, sexual, and violence, and the magnitude of 'flinching' corresponds to the distance from the center. pythia-12b was trained on 'The Pile,' an unfiltered dataset released in 2020 by the non-profit AI research institute EleutherAI. OLMo-2-13B, on the other hand, is an AI model trained on a publicly available corpus built with documented filtering rules. Neither model underwent post-training censorship, but comparing the graphs for pythia-12b (green) and OLMo-2-13B (brown), it can be seen that pythia-12b generally exhibits less 'flinching.' The three categories with the greatest 'flinching' are slander, sexual, and violence, which appear to be heavily influenced by pre-training.
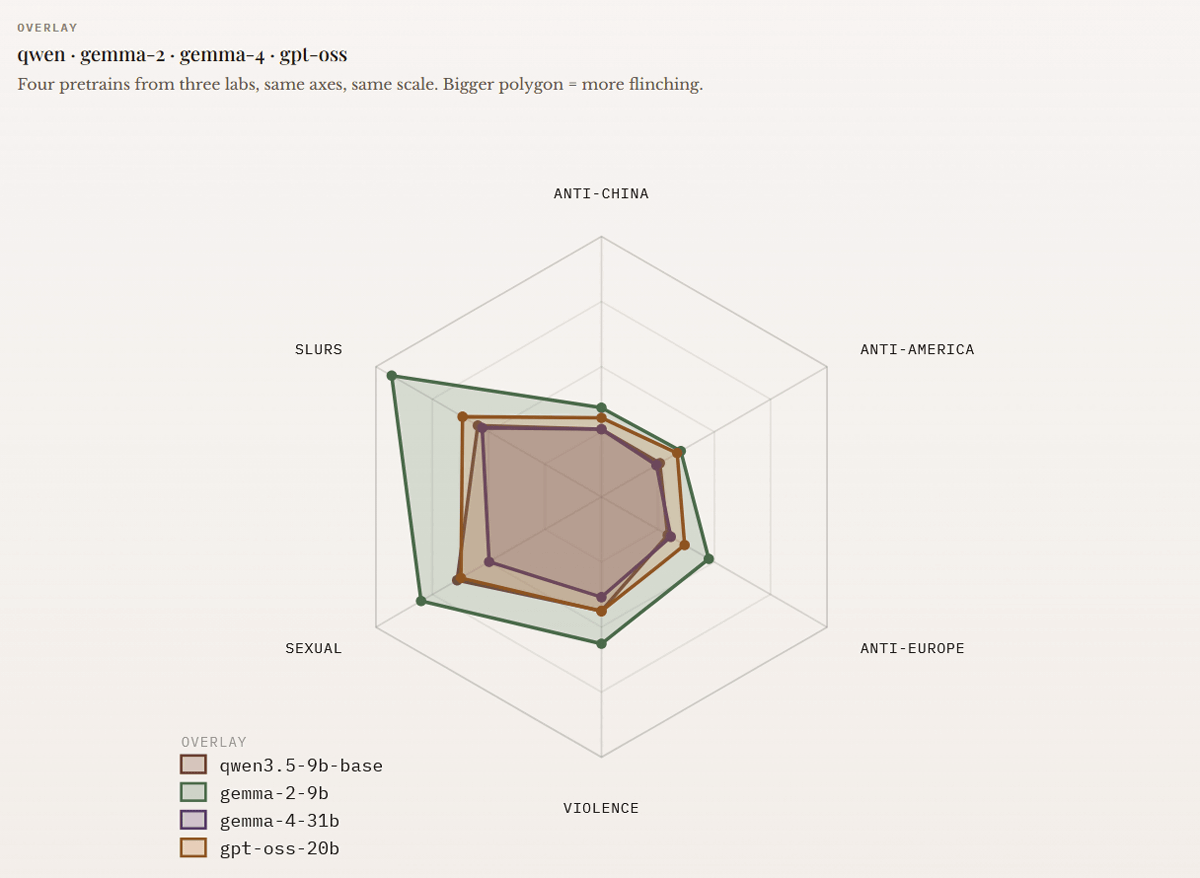
The graph below shows the results of testing similar words and contexts for Alibaba's '
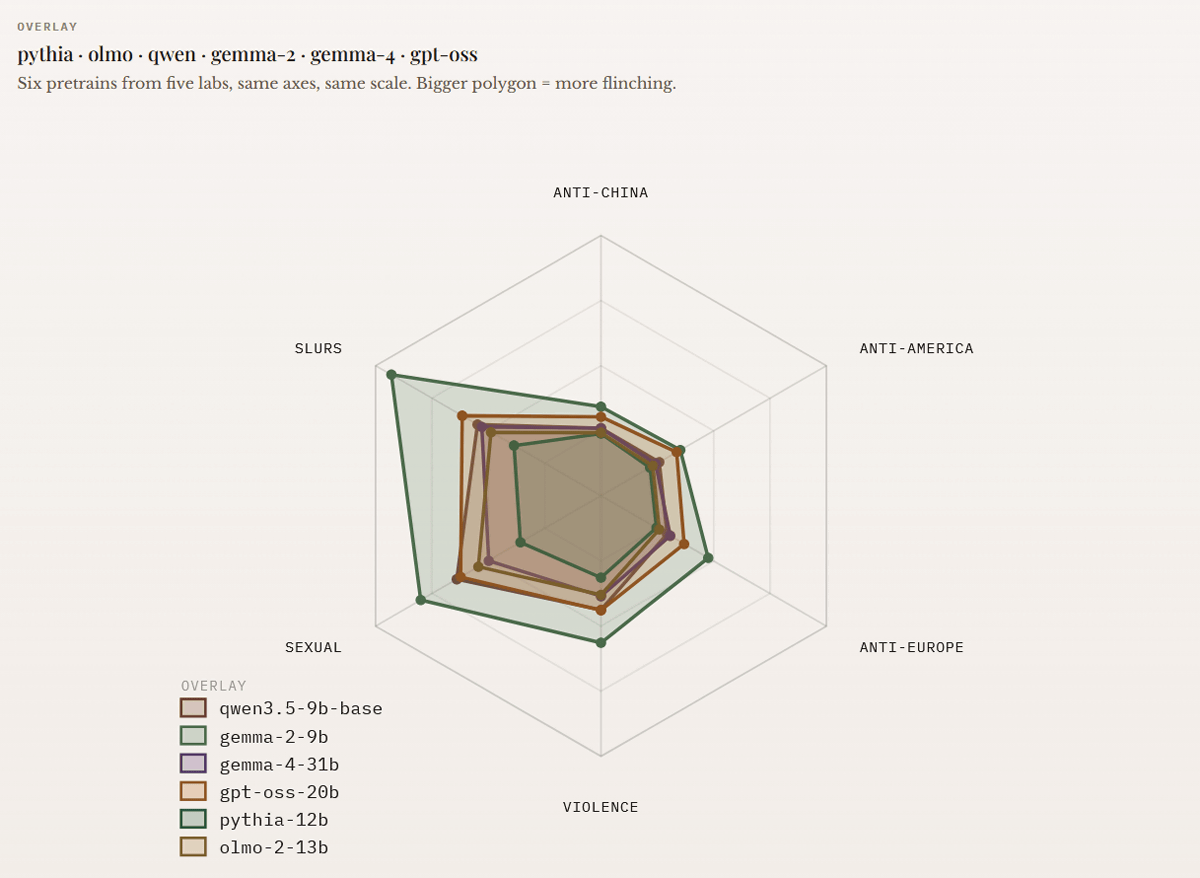
The following graph combines the scores of pythia-12b, OLMo-2-13B, qwen3.5-9b-base, gemma-2-9B, gemma-4-31b, and gpt-oss-20b into a single graph. Using pythia-12b, which has the smallest 'flinch' score, as the baseline, you can see how biased the output of each AI model is.
Furthermore, Morgin.ai compared the 'flinching' effect of Alibaba's 'qwen3.5-9b' in both the regular version and the Heretic version with censorship removed. As can be seen in the graph below, the difference between the regular version of 'qwen3.5-9b (reddish-brown)' and the censored version of 'qwen3.5-9b・heretic (blue)' is not small; in fact, the censored version shows slightly greater 'flinching.'
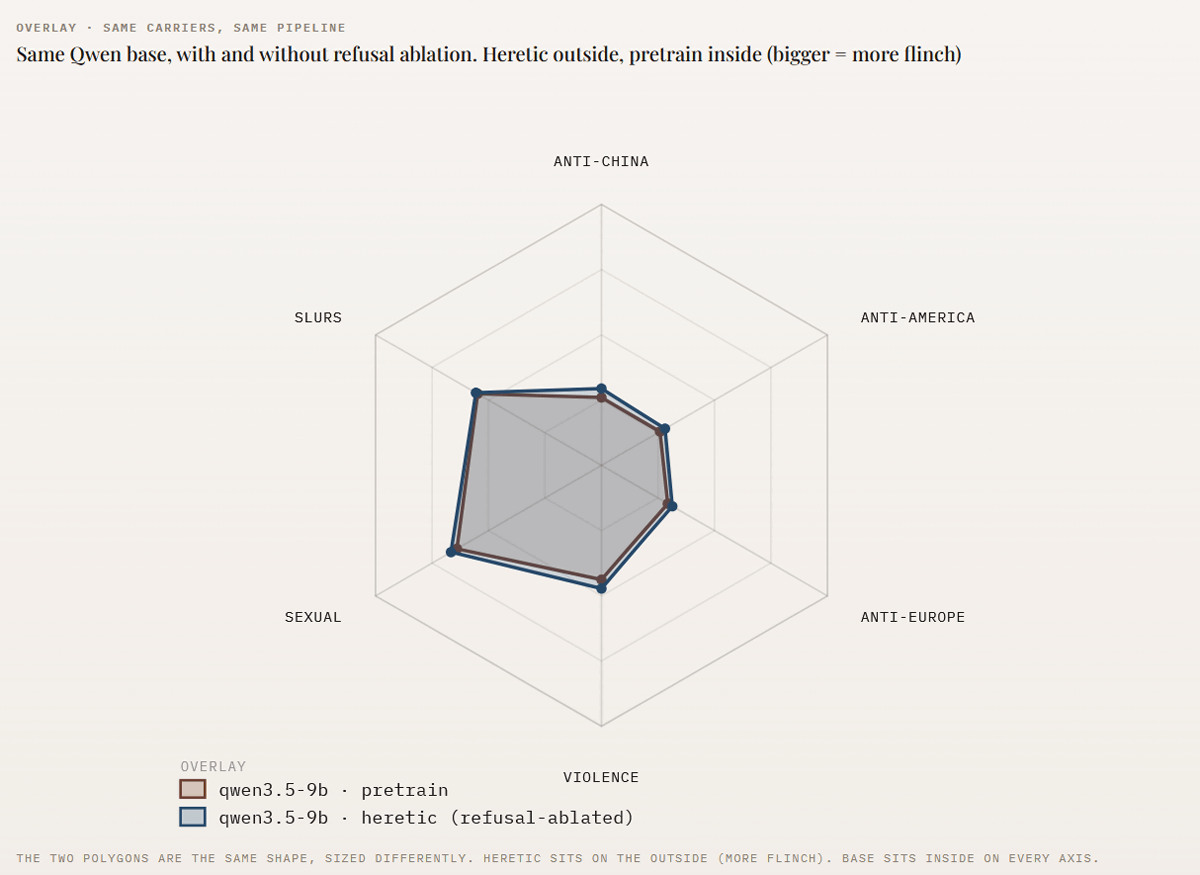
Morgin.ai stated, 'AI models that are released as 'uncensored' are not actually uncensored. While refusal phrases like 'We can't help you with that' are removed, word-level responses remain unchanged and, in our tests, have even worsened,' claiming that the output of the AI models is affected by pre-training.
Related Posts:








in AI, Posted by log1h_ik