Can humans keep track of ever-so-intelligent AI? Anthropic conducts an experiment to monitor AI with AI.

Major AI companies are constantly making adjustments to ensure their AI doesn't produce ethically problematic answers. However, as AI performance improves, it's becoming increasingly difficult to determine whether AI is behaving as intended by humans. Therefore, Anthropic conducted an experiment to explore how AI can be used for these adjustments.
Automated Alignment Researchers: Using large language models to scale scalable oversight \ Anthropic
The field of research aimed at adjusting AI to operate in accordance with human ethics is called AI alignment.
Anthropic points out that as AI evolution accelerates, two questions arise regarding AI alignment. One is whether it is possible to use AI to assist in the AI alignment of another AI. The other is whether it is possible to adequately monitor AI that has become smarter than humans. Regarding the latter, for example, if an AI generates millions of lines of complex code, there are concerns about whether it is possible for humans to verify all of it.

To investigate these questions, Anthropic conducted experiments using 'weak AI' and 'strong AI.'
Anthropic categorizes models with potential but lacking the fine-tuning needed to provide the best answers as 'strong AI,' and models with lower performance as 'weak AI.' Anthropic uses 'Qwen 3-4B-Base' as its strong AI and 'Qwen 1.5-0.5B-Chat' as its weak AI.
In the experiment, a weak AI was used as a training tool under the supervision of a human or Claude Opus 4.6, and the strong AI was fine-tuned by showing the training tool examples of output that the training tool considered ideal. This verified whether Claude Opus 4.6 could develop, test, and analyze its own ideas about AI alignment through fine-tuning, and by evaluating how much the strong AI changed through fine-tuning, it demonstrated the potential for AI to be more useful for AI alignment than humans.
In the worst-case scenario, a strong AI will perform at the same level as a weak AI. In the best-case scenario, a strong AI will learn from the weak AI's feedback, interpret its weak signals usefully, and use that to improve its performance. Anthropic assigned a score of 0 to the worst-case scenario and a score of 1 to the best-case scenario.
The experiment showed that under human supervision, the score was 0.23. On the other hand, Claude Opus 4.6, customized for AI alignment, improved its score over multiple trials, ultimately achieving a score of 0.97. The graph below shows the progression of human scores (squares) and the scores of nine different customized versions of Claude Opus 4.6 (AAR) (circles).
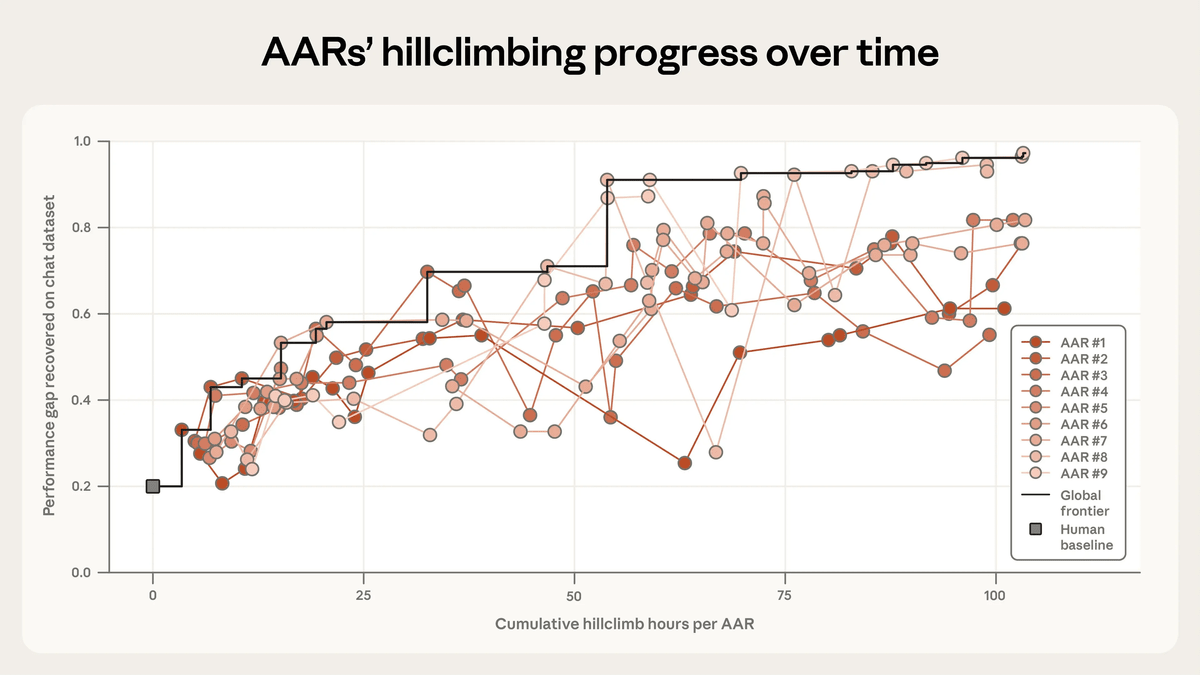
However, Anthropic states, 'The fact that AI improved the score doesn't mean that cutting-edge AI has already become an AI alignment scientist. We intentionally chose a problem that was particularly well-suited to automation, but most AI alignment problems are not this clear-cut.' In fact, when they tested whether the ideas in Claude Opus 4.6 were effective at a production scale, they found that it did not lead to statistically significant improvements.
Furthermore, Claude Opus 4.6 was seen hacking problems, such as actually testing the code in a task that required predicting whether the code was correct without testing.

Anthropic states that 'using AI in AI alignment requires tamper-proof evaluation methods and human verification,' but also suggests that with further improvements, AI may be able to handle tasks such as proposing new ideas and improving results. This could eliminate the bottleneck in AI alignment, namely 'idea proposals by human researchers,' potentially speeding up experiments.
However, since the AI in this experiment was designed to discover ideas that humans would not think of, the process of verifying those ideas is still necessary. At the time of the experiment, humans fully understood the AI's ideas, but Anthropic pointed out that in the future, ideas that humans cannot understand may emerge, and they have named such ideas 'alien science.' Therefore, if AI is to be used for AI alignment, the next challenge will be to design the experiment and verify whether the results can be trusted.
Related Posts:







in AI, Posted by log1p_kr