This interactive guide explains 'MicroGPT,' a tool that can perform GPT training and inference using only 200 lines of pure Python code.
According to its creator,
MicroGPT explained interactively | growingSWE
https://growingswe.com/blog/microgpt
◆What kind of model is MicroGPT?
MicroGPT aims to generate names that sound like real names by learning statistical patterns from 32,000 names. It uses a dataset of real names such as 'emma,' 'olivia,' 'ava,' 'isabella,' and 'sophia' for training, and once training is complete, the model will be able to generate 'name-like' names such as 'kamon,' 'karai,' 'anna,' and 'anton.' From ChatGPT's perspective, both the 'training names' and the 'output names' are simply documents. When prompts are entered, the model responds with statistical document completion based on its learned information, such as 'which characters tend to follow which others,' 'which sounds tend to be used at the beginning and end,' and 'what is the typical length of a name.'
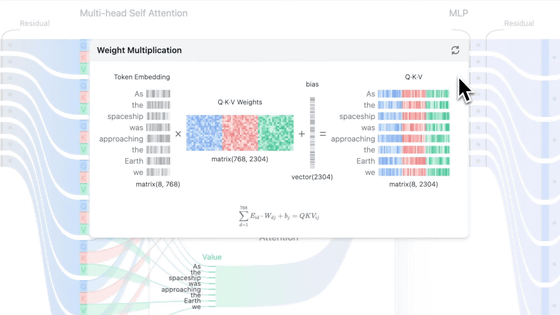
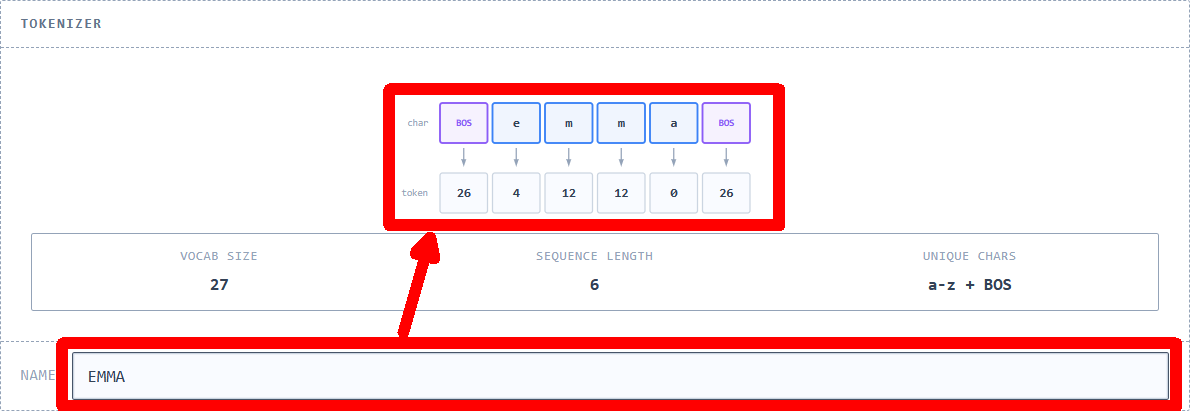
◆ Tokenizer
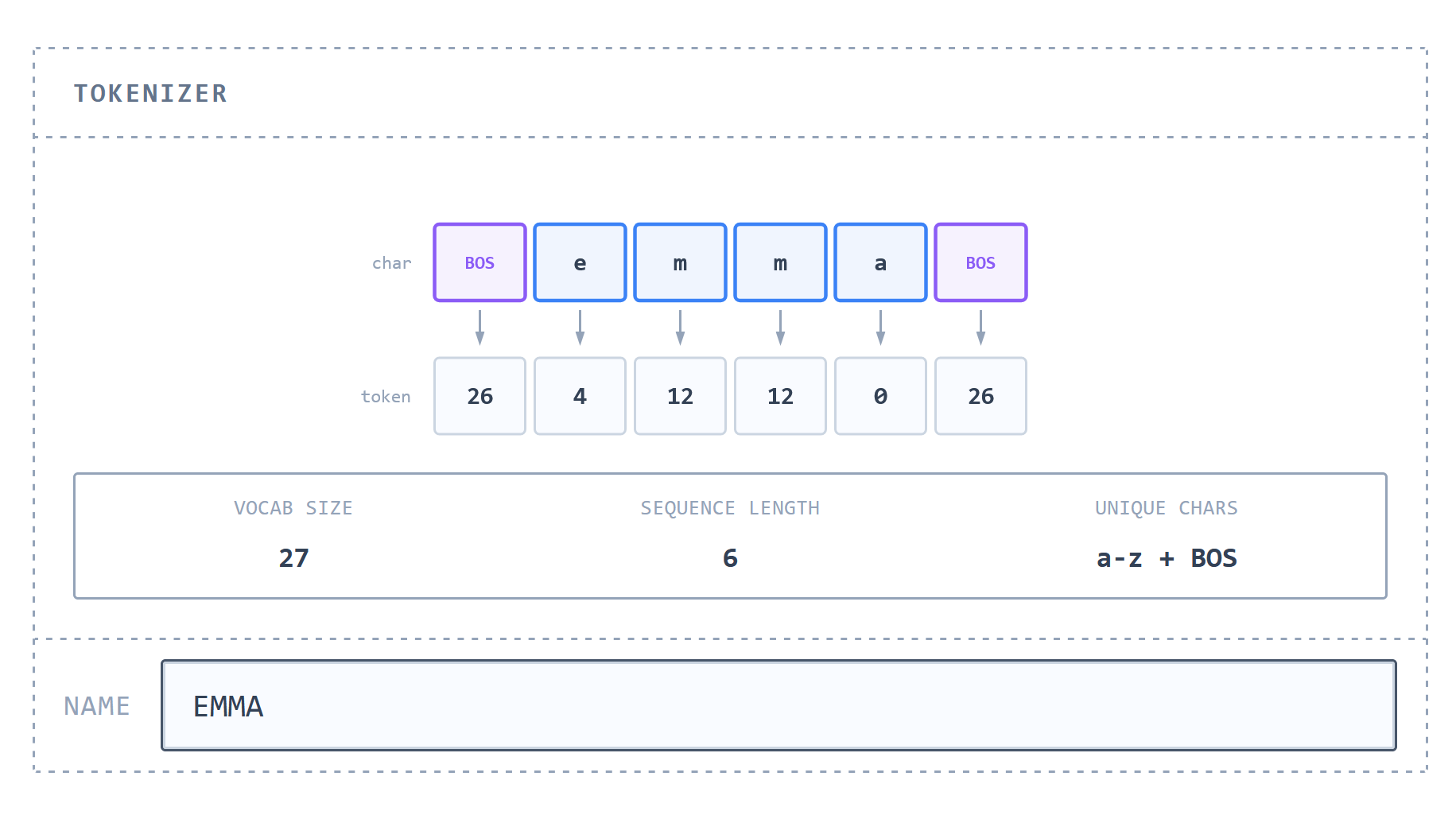
Neural networks don't handle characters directly, but rather as numerical values. Therefore, a mechanism is needed to convert strings into sequences of integers, and conversely, to generate strings from sequences of integers. The simplest mechanism for a 'tokenizer,' which converts personal names into tokens to be passed to the model, is to 'assign one integer to each character in the dataset.' By limiting the characters used to lowercase alphabets and assigning a numerical ID from '0' to '25' to each of the 26 characters, these become tokens. Furthermore, a special token called ' BOS (Beginning of Sequence) ' is added with ID '26' and placed at the beginning and end positions of the name string. It's important to note that the numbers themselves and their magnitudes have no meaning; they are merely IDs to identify characters. Practical tokenizers such as
The following diagram visualizes how the tokenizer works. On the original site, you can see how the name entered in 'NAME' is tokenized.
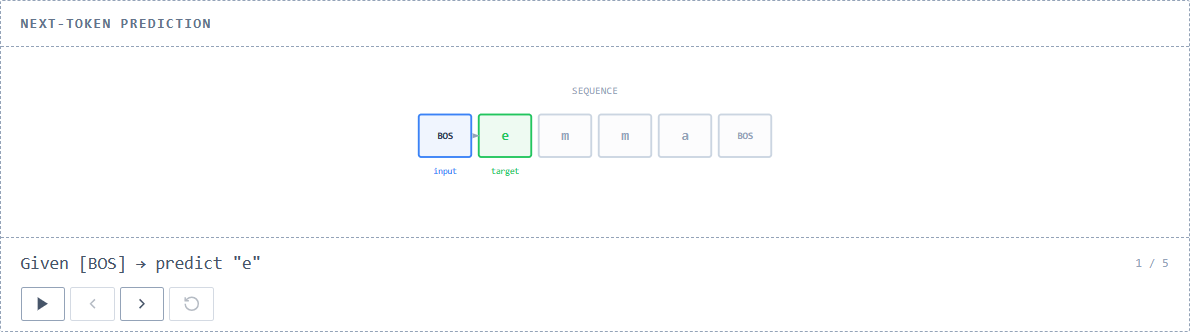
◆Predict the next token
A crucial task for a model that returns something resembling a person's name is 'to predict what the next token will be, given a given token.' This involves shifting the position of each token in the given sequence, checking the tokens one by one, and predicting the token at the next position. Since BOS is always set at position 0, the first position, the model predicts the token following BOS, i.e., the first character.
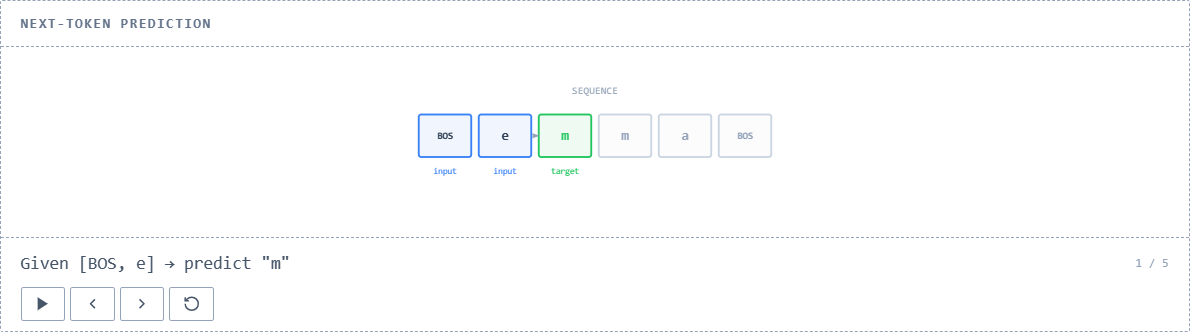
Next, we focus on position 1 and predict the next token based on BOS and the token after it.
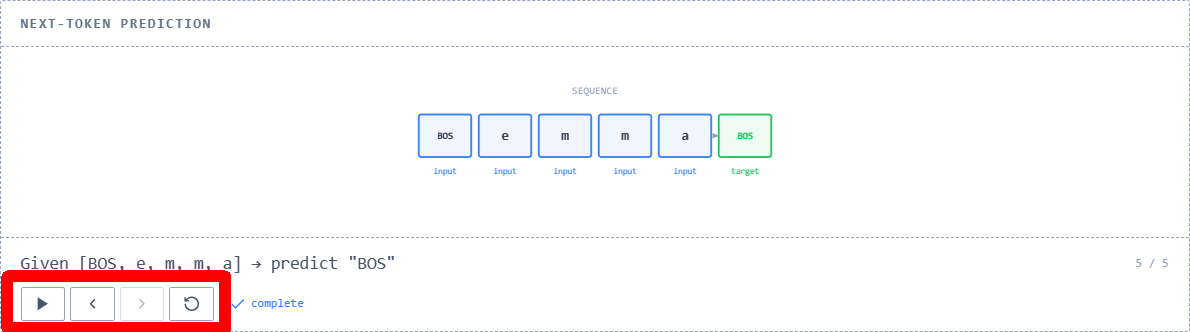
By performing similar processes sequentially, the context expands and continues until the final BOS is predicted. This series of processes is called a sliding window and is used for training all LLMs, including ChatGPT. On the original site, the four buttons in the lower left of the diagram are assigned the functions of 'Play Animation,' 'Go Back to Previous Frame,' 'Go Forward to Next Frame,' and 'Go Back to Top' from left to right, respectively, and when the animation is played, the content and explanation of the diagram are updated according to the progress of the process.
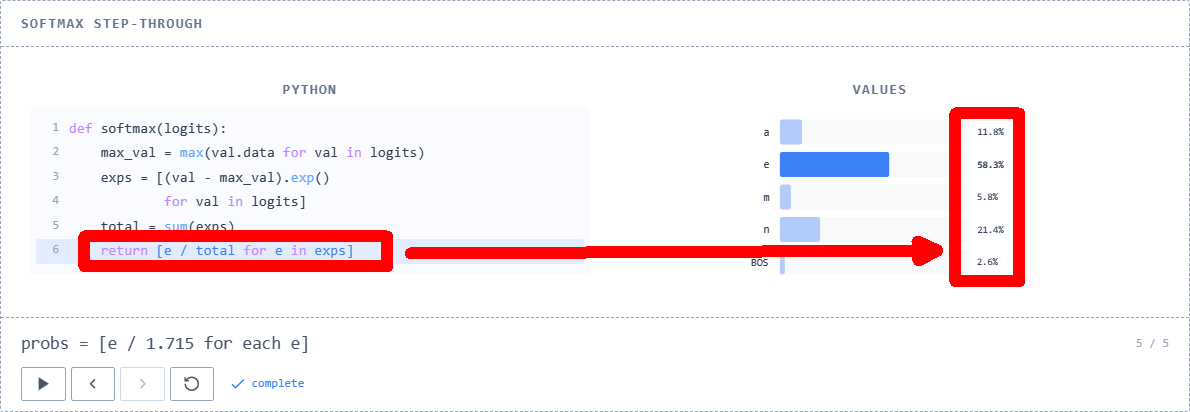
◆ Convert score to probability
When predicting the next token, the model outputs one of 27 raw numbers at each position, with the probability of each token being output being between 0 and 1. Instead of using the probability values directly, they are first scored using
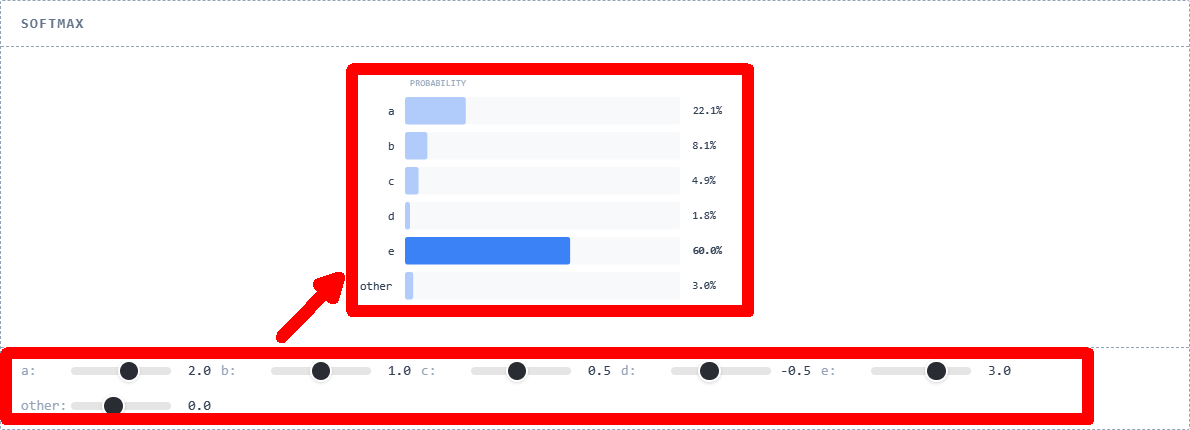
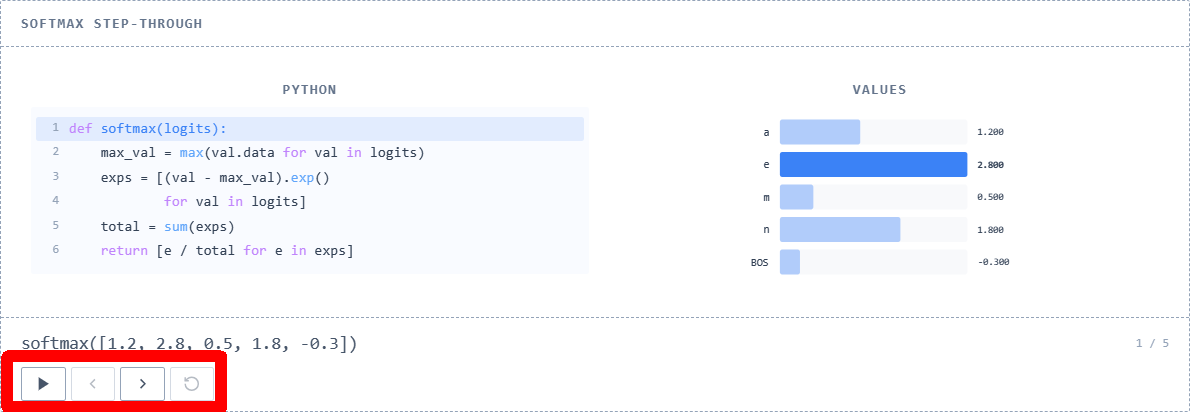
The process described above is called '
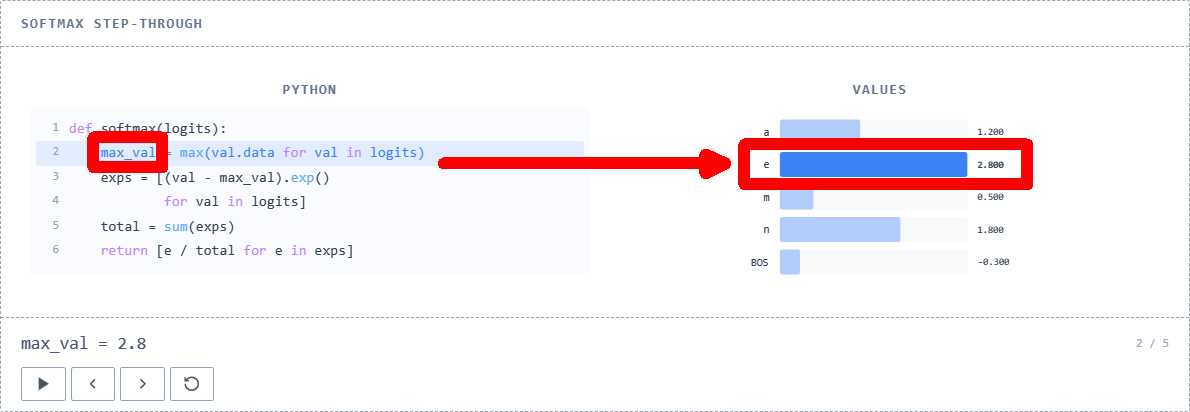
First, the function finds the maximum value from the array of score values passed to it.
Next, we calculate
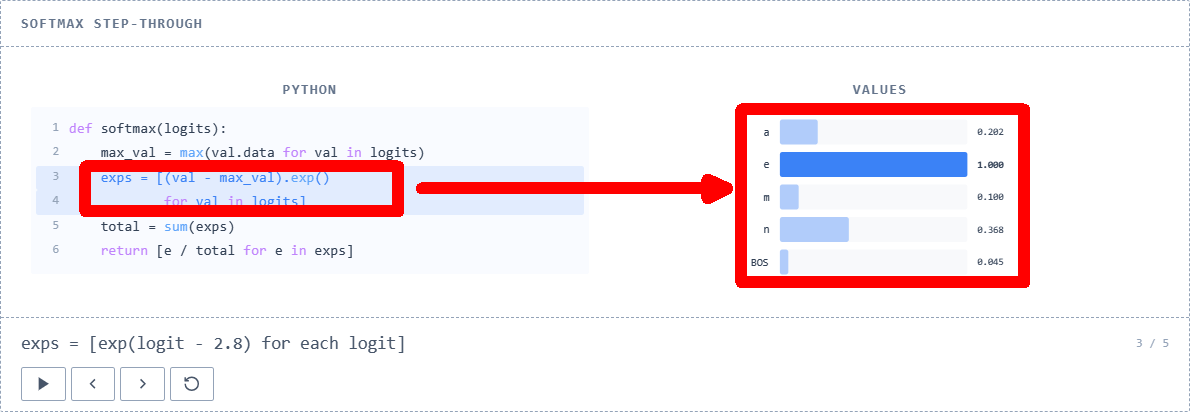
We sum up each value in the array of natural logarithms and find the total value.

Finally, we divide each value in the natural logarithm array by its sum to obtain an array of probabilities.
◆Tie
The original site's explanation continues, but you'll understand it better if you actually experience the 'interactive explanation,' so please visit the original site to check out the rest.
Related Posts: