Essential AI announces 'Rnj-1', an 8 billion parameter open AI model with performance similar to GPT-4o, and its CEO is part of the team that invented Transformer
Essential AI
https://essential.ai/research/rnj-1

Today, we're excited to introduce Rnj-1, @essential_ai 's first open model; a world-class 8B base + instruct pair, built with scientific rigor, intentional design, and a belief that the advancement and equitable distribution of AI depend on building in the open.
— Essential AI (@essential_ai) December 6, 2025
We bring… pic.twitter.com/VpUHent2w8
Essential AI is an American AI company that is concerned about the control of the production and distribution of advanced AI technology by a small number of companies, and aims to build an open platform to promote and accelerate AI breakthroughs on a global scale. CEO Ashish Vaswani was part of the team that developed Transformer at Google and is one of the co-authors of the paper 'Attention Is All You Need,' which introduced Transformer to the public.
Why did the researchers behind Transformer, which had a major impact on the advancement of generative AI, leave Google? - GIGAZINE

Essential AI announced 'Rnj-1' on December 6, 2025, as a language model contributed to open source. It combines a world-class base model with a large-scale, instruction-tuned language model. The name Rnj-1 is said to come from Srinivasa Ramanujan , a legendary Indian mathematician.
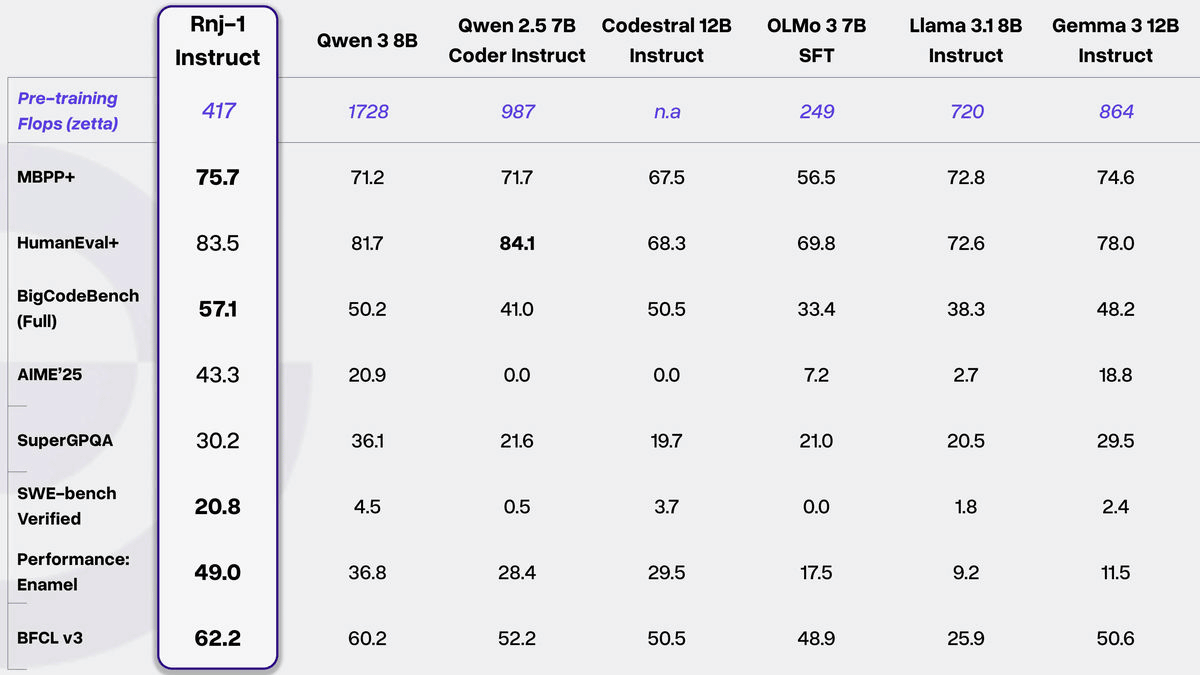
Rnj-1 consists of a pair of a base model and an Instruct model fine-tuned to follow instructions. Rnj-1 is an 8 billion parameter model that follows the architecture of Google's open source large-scale language model ' Gemma 3. ' By adopting 'YaRN,' a technology for handling long texts, it is designed to be able to process long contexts of up to 32,000 tokens. This gives it an advantage in tasks that require reading long sentences and documents, as well as long conversations and multi-step interactions.
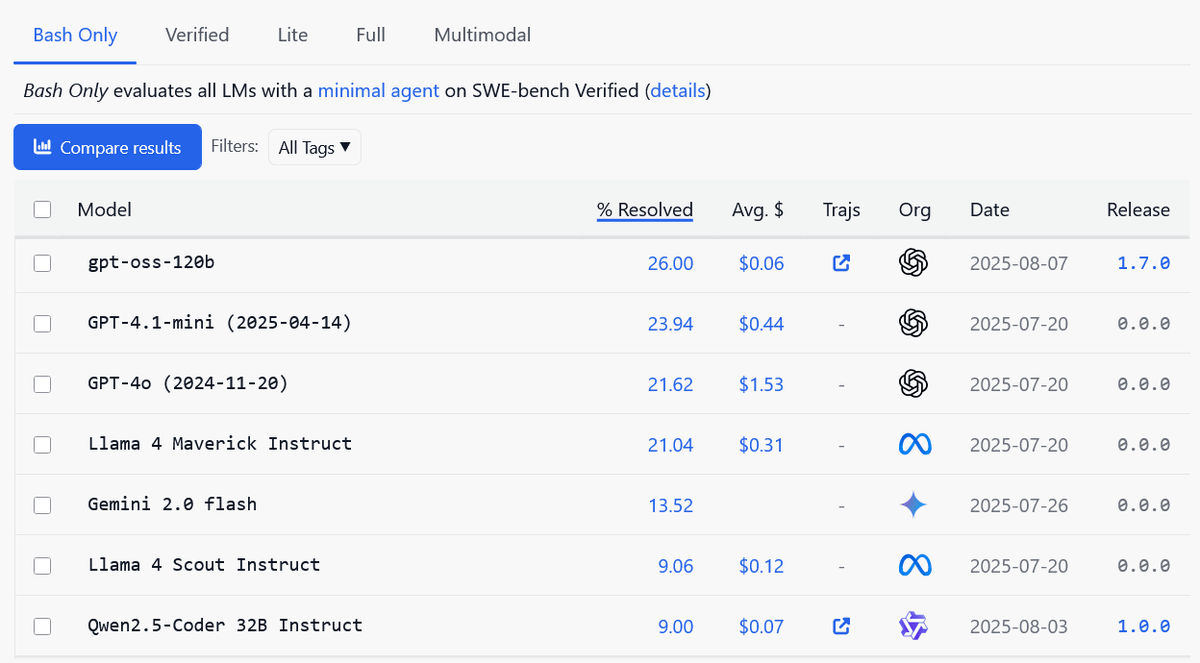
Additionally, in algorithmic code generation and broader coding tasks, both Rnj-1 Base and Instruct performed comparable to the best open weight models of their size, and outperformed even larger models, including models with 20 billion parameters. Furthermore, in agent coding, one of Essential AI's goals, Rnj-1 demonstrated exceptional performance, achieving a score of 20.8% in the bash-only mode of SWE-bench, which measures agent performance. Essential AI claims that Rnj-1 performed on a par with Gemini 2.0 Flash and GPT-4o, based on the scores of other AI models.
Rnj-1 also excels at solving math and science problems. On Minerva-MATH, which measures 'undergraduate to graduate-level mathematical and quantitative reasoning ability,' it performed on par with similar open weight-based models. It also performed near the top of similar models on GPQA-Diamond, a 'challenging doctoral-level problem set covering biology, physics, and chemistry.'
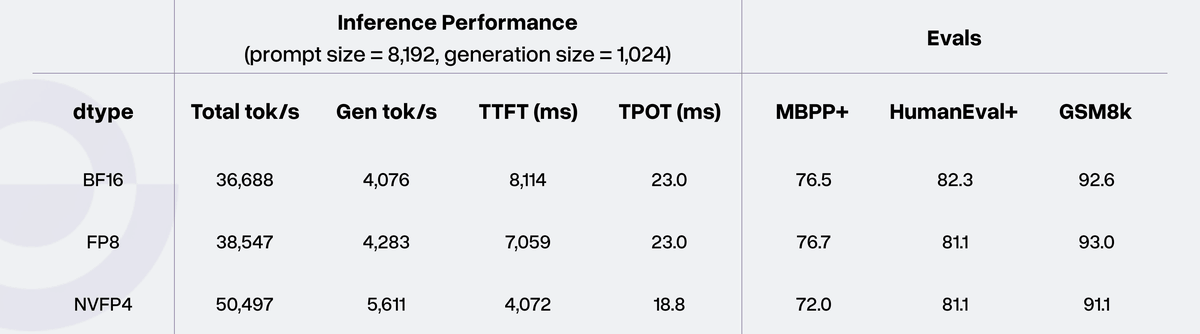
Furthermore, Rnj-1 is designed to be resistant to quantization after training and during inference. Normally, selecting a lighter calculation method (lower precision) increases calculation speed but makes the answers more susceptible to distortion. However, Rnj-1 has the advantage that it can significantly increase processing speed while maintaining roughly the same quality, even when the calculation precision is reduced from 16 bits to 8 bits to 4 bits. This has the advantage of significantly increasing the number of characters that can be generated per second (token throughput) when processing large amounts of text all at once.
'We are incredibly excited and proud to share our first flagship model, the Rnj-1. The Rnj-1 is the culmination of 10 months of hard work by an incredible team,' said Vaswani. Essential AI's Yash Vanjani added, 'The Rnj-1 is a major milestone for Essential AI and shows how far we can go with a small team of 20 people. It's been an honor to work with some of the best people in the AI field!'
We are beyond thrilled to share our first flagship models, Rnj-1 base and instruct 8B parameter models. Rnj-1 is the culmination of 10 months of hard work by a team phenomenal, dedicated to advancing American SOTA OSS AI.
— Ashish Vaswani (@ashVaswani) December 6, 2025
Lots of wins with Rnj-1.
1. SWE bench performance close… https://t.co/ZYKOj4zmXr
Rnj-1 is licensed under the Apache License Version 2.0 and is available for download from Hugging Face. According to CEO Vaswani, a technical report on Rnj-1 will be released soon. Looking ahead, he said, they plan to focus on expanding and strengthening the model's capabilities to handle longer contexts, achieving 'low-precision training' to reduce memory usage and increase computational speed, advancing compression theory, and expanding the types and range of program behaviors they want to simulate.
EssentialAI/rnj-1 · Hugging Face
https://huggingface.co/EssentialAI/rnj-1
EssentialAI/rnj-1-instruct · Hugging Face
https://huggingface.co/EssentialAI/rnj-1-instruct
Regarding Rnj-1, Kalyan KS, a consultant and researcher in natural language processing, said, 'Rnj-1 may be the best open source LLM built in the United States. However, it lacks comparison with the recently released Ministral 3 8B instruction .'
Rnj-1, possibly the best open-source LLM built in USA.
— Kalyan KS (@kalyan_kpl) December 6, 2025
Interesting, Rnj-1's architecture is similar to Gemma 3, except that it uses only global attention, and YaRN for long-context extension.
But, comparison with the recently released Ministral 3 8B instruct model is missing… https://t.co/K8JpBYpFHh
Related Posts:







in AI, Posted by log1e_dh