Huawei announces 'SINQ,' an open-source quantization method that reduces memory usage of AI models by 60-70% and enables them to run on inexpensive, low-performance hardware

Huawei, a major Chinese technology company, has announced Sinkhorn-Normalized Quantization (SINQ) , a quantization technique that enables large-scale language models (LLMs) to run on consumer-grade hardware without compromising quality.
[2509.22944] SINQ: Sinkhorn-Normalized Quantization for Calibration-Free Low-Precision LLM Weights
Huawei's SINQ: The Open-Source Shortcut to Shrinking LLMs Without Sacrificing Power - AI Consultant | Machine Learning Solutions | Expert Developers
https://aisengtech.com/2025/10/04/Huawei-s-SINQ-The-Open-Source-Shortcut-to-Shrinking-LLMs-Without-Sacrificing-Power/
Huawei's new open source technique shrinks LLMs to make them run on less powerful, less expensive hardware | VentureBeat
https://venturebeat.com/ai/huaweis-new-open-source-technique-shrinks-llms-to-make-them-run-on-less
Huawei invests more than $22 billion (approximately 3.3 trillion yen) in research and development annually. One of Huawei's leading innovation research facilities is the Huawei Research Center Zurich (ZRC), located in Zurich, Switzerland. ZRC has announced 'SINQ,' an open-source quantization method designed to reduce the memory footprint of LLMs without compromising output quality. The greatest advantages of SINQ are its high speed, calibration-free nature, and ease of integration into existing model workflows.
While traditional quantization methods reduce the accuracy of AI model weights to save memory, they suffer from the trade-off between memory usage and performance. However, SINQ successfully reduces performance degradation by introducing the following two key innovations:
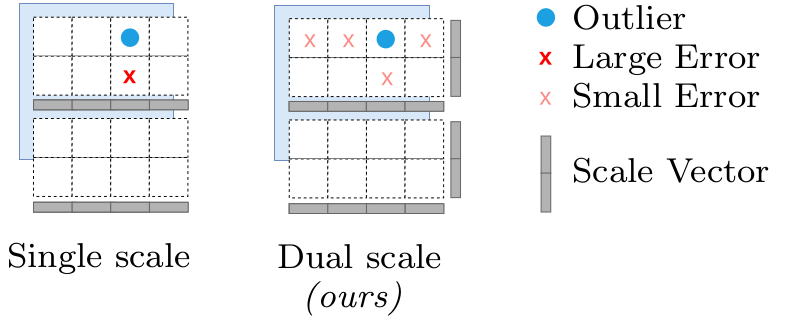
- Two-axis scaling
When quantizing a matrix, SINQ uses separate scaling vectors for rows and columns instead of a single scale factor, an approach that reduces the impact of outliers and allows the quantization error to be more flexibly distributed across the matrix.
-
Sinkhorn-Knopp normalization is a fast algorithm inspired by an algorithm called Sinkhorn iteration. It minimizes 'matrix imbalance' by normalizing the standard deviations of the rows and columns of a matrix. It has been shown to improve quantization performance more effectively than alternative metrics such as kurtosis .

As a result, SINQ outperformed uncalibrated quantization methods across multiple benchmarks, consistently improving perplexity, a measure of how accurately a probabilistic model can predict samples , and flip rate, a measure of model robustness.
By using SINQ, AI models of various sizes can successfully reduce memory usage by 60-70% depending on the architecture and bit width. In other words, AI models that previously required more than 60GB of memory can now run on around 20GB. SINQ has been successfully used with a wide range of AI models, including the Qwen3 series, Llama , and DeepSeek 's LLM.
'This means that AI models that previously required high-end enterprise GPUs can now run on cheaper consumer GPUs,' said AI consultant Shen Gao . This is like taking an AI model that previously required NVIDIA's AI GPUs, the A100 80G ($19,000) or H100 ($30,000), and making it run on a GeForce RTX 4090.
Amazon | ASUS TUF GeForce RTX® 4090 OC Edition Gaming Graphics Card (PCIe 4.0 24GB GDDR6X HDMI 2.1a DisplayPort 1.4a) | ASUS | Graphics Card Online Store
Also, A100-based instances often cost between $3 and $4.50 per hour, while a 24GB GPU like the GeForce RTX 4090 is available for around $1 to $1.50 per hour. Especially for extended inference workloads, this difference can translate into thousands of dollars in cost savings over time.
This allows LLM to run on small clusters, local workstations, and consumer-grade setups that are otherwise memory-constrained.
SINQ is available on platforms such as GitHub and Hugging Face under the Apache 2.0 license , meaning it is free to use, modify, and deploy commercially.
Paper page - SINQ: Sinkhorn-Normalized Quantization for Calibration-Free Low-Precision LLM Weights
https://huggingface.co/papers/2509.22944
GitHub - huawei-csl/SINQ: Welcome to the official repository of SINQ! A novel, fast and high-quality quantization method designed to make any Large Language Model smaller while preserving accuracy.
https://github.com/huawei-csl/SINQ
Related Posts:







