'Stable Audio 2.5' is a music generation AI that can generate commercial-quality music in under two seconds.

Stability AI, known for developing the image generation AI 'Stable Diffusion,' released its music generation AI ' Stable Audio 2.5 ' on September 10, 2025. Stability AI touts it as 'the first music generation model designed for creating sound for corporate brand images and advertising.'
Stability AI Introduces Stable Audio 2.5, the First Audio Model Built for Enterprise Sound Production at Scale — Stability AI
Today we're launching Stable Audio 2.5: The first audio model built for enterprise-grade sound production 🔊
— Stability AI (@StabilityAI) September 10, 2025
Audio influences brand engagement by 86%, but few enterprises are leveraging audio as an extension of their brand, making customized sound an untapped differentiator.… pic.twitter.com/lCiSOO4RT2
Stability AI states, 'Audio influences 86% of brand engagement, but few companies utilize audio as an extension of their brand, making customized sound an untapped differentiator,' highlighting the importance of customizable, high-quality audio. According to Stability AI, Stable Audio 2.5 is the first audio generation model in the Stable Audio series designed for enterprise-grade sound production, delivering improved quality and control to meet the demand for dynamic configurations that can be adjusted to suit the needs of brands.
The features of Stable Audio 2.5 are as follows:
- Generate up to 3 minutes of tracks in under 2 seconds
Post-trained using the state-of-the-art Adversarial Relativistic-Contrastive (ARC) method developed by the Stable Audio research team, Stable Audio 2.5 achieves high-speed inference, generating up to three minutes of tracks in under two seconds. Stability AI claims that the ARC method is 'the fastest text-to-speech model we know of.'
- Dynamic and customizable music generation
Stable Audio 2.5 is optimized for music, improving musical structure and enabling the generation of songs divided into multiple parts such as intros, developments, and outros. It also responds better to prompts, improving response to mood descriptions such as 'uplifting' and genre-crossing musical expressions such as 'rich synthesizers.'
- Audio inpainting support for greater control
In addition to text-to-audio and audio-to-audio workflows, Stable Audio 2.5 supports 'audio inpainting,' which allows users to input their own audio, specify the starting point, and the model will generate the rest of the track based on the context. To prevent users from 'inputting part of an existing song and then modifying the rest,' the terms of use prohibit the input of copyrighted content, and the system uses advanced content recognition technology to check for copyright infringement.
You can try Stable Audio 2.5 at StableAudio.com or get an API key from the Stability AI API .
Stable Audio - Generative AI for music & sound fx
https://stableaudio.com/
The steps to use Stable Audio can be easily understood by looking at the following article.
I tried using the music generation AI 'Stable Audio 2.0' that can create music just by giving instructions in text - GIGAZINE
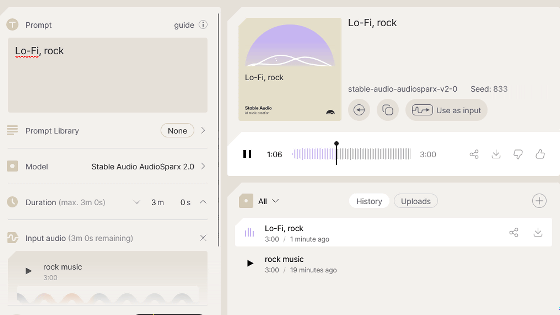
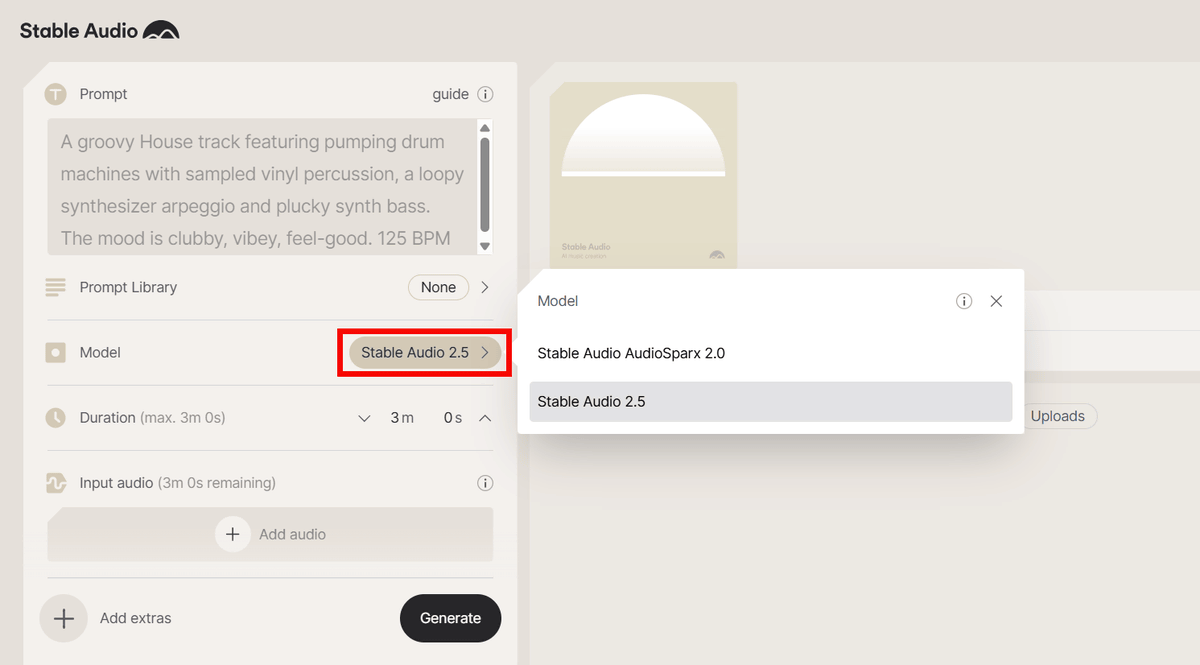
I visited StableAudio.com and found that the Stable Audio 2.5 was available as a model option.
Related Posts:







in Software, Posted by log1e_dh