Meta Announces DINOv3 Visual Language Model, Self-Supervised Learning from Unlabeled Images for High Performance on a Variety of Tasks

Training image generation AI or image analysis AI requires a large amount of data, where images of cats are manually labeled with labels such as 'cat,' 'walking,' and 'striped.' However, Meta's DINOv3 model was trained using 1.7 billion unlabeled images, and can perform a variety of label-independent tasks without human intervention, outperforming specialized models.
DINOv3: Self-supervised learning for vision at unprecedented scale

Introducing DINOv3: a state-of-the-art computer vision model trained with self-supervised learning (SSL) that produces powerful, high-resolution image features. For the first time, a single frozen vision backbone outperforms specialized solutions on multiple long-standing dense… pic.twitter.com/nwS3zFCaaN
— AI at Meta (@AIatMeta) August 14, 2025
DINOv3 | Research - AI at Meta
https://ai.meta.com/research/publications/dinov3/
AI training for visual tasks typically relies on 'human-labeled images,' which can ignore information not explicitly mentioned in text and can be difficult to accurately label specialized video. DINOv2 , the predecessor to DINOv3, uses self-supervised learning to generate more accurate segmentations from dynamic video than previous methods. Because it can self-train without human labeling, it can fully incorporate data that is beyond the reach of human explanations.
Meta announces video processing model 'DINOv2', and in the future, AI may be able to create immersive VR environments - GIGAZINE

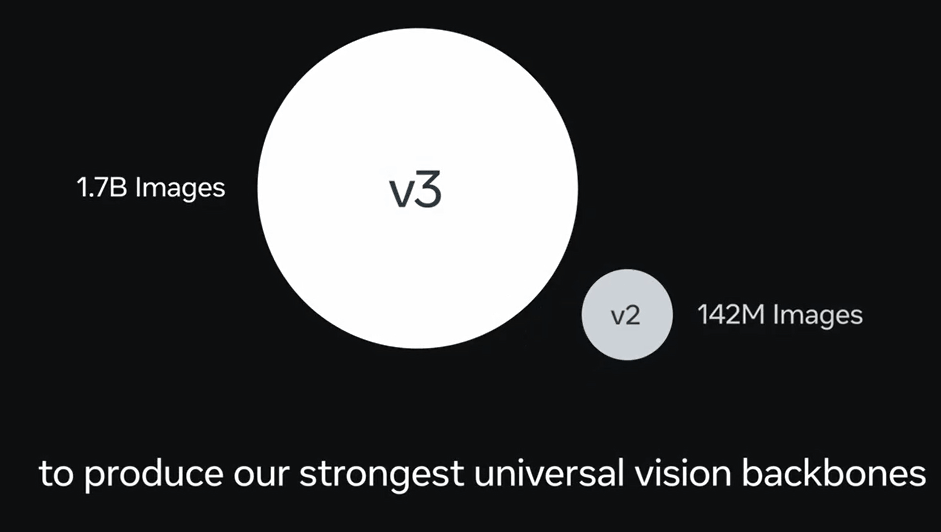
DINOv3 is a further development of DINOv2. The first major difference is that thanks to an innovative training technique that does not require labeled data, the model size has been expanded by approximately 7 times, from approximately 1.1 billion parameters in DINOv2 to approximately 7 billion parameters in DINOv3.

In addition, the amount of data used for training increased by approximately 12 times, from approximately 142 million images for DINOv2 to approximately 1.7 billion images for DINOv3.
When loading images or videos, it is usually necessary for a human to manually label the data.

DINOv3 eliminates the need for labeling and allows the model to learn every detail, including the background. It also uses self-supervised learning, allowing the model to create its own pseudo-tasks for learning, such as hiding part of an image and predicting from the rest, or rotating and cropping the same image to learn its features.

The results below show the performance of DINOv3 against DINO, DINOv2, Google DeepMind's
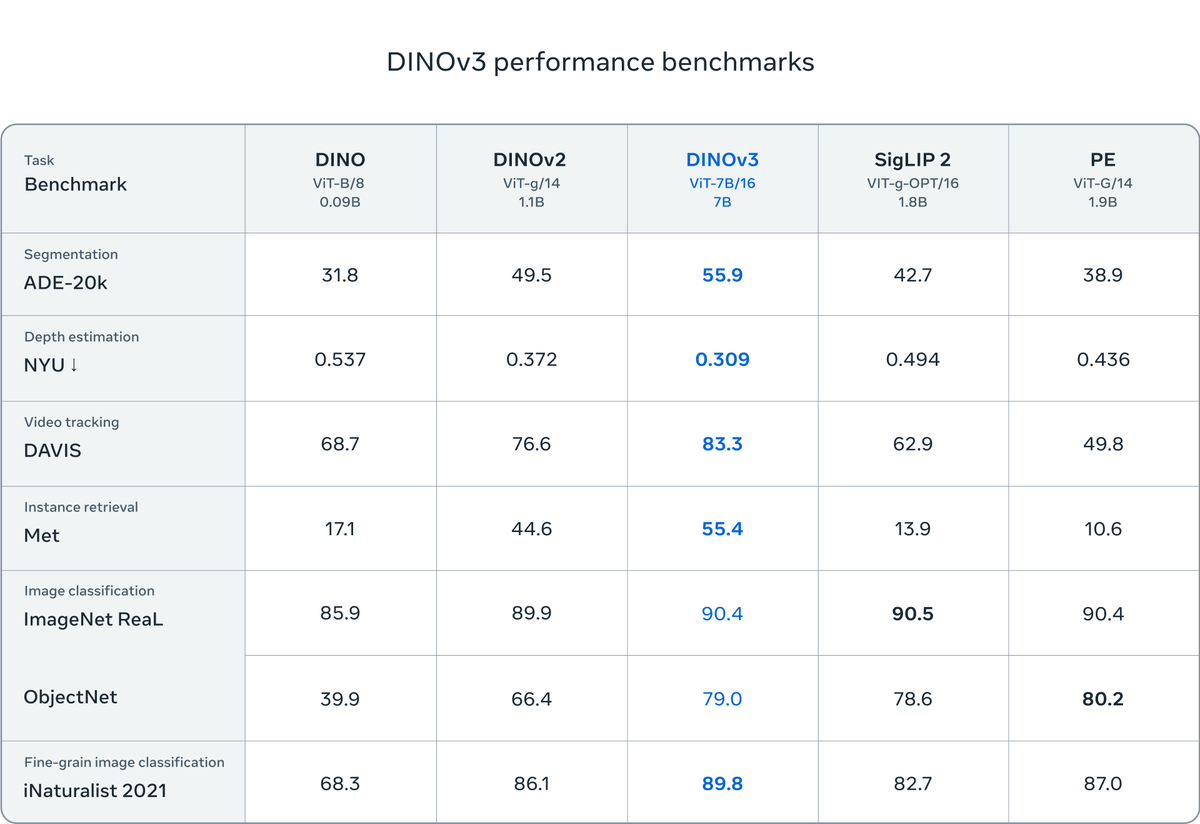
According to Meta, DINOv3 outperformed dedicated solutions in tasks such as classification and extraction of elements from images and videos, as well as dense prediction tasks. DINOv3 is expected to not only accelerate existing use cases, but also lead to advancements in a variety of industries, including healthcare, environmental monitoring, autonomous vehicles, retail, and manufacturing.
Additionally, because DINO's approach is not specialized for any particular type of image, it can be applied to other fields where labeling is extremely difficult or expensive, such as histology, endoscopy, and medical imaging. Additionally, even for satellite and aerial imagery, where manual labeling is impractical due to the sheer volume and complexity of the data, DINOv3 can train a single backbone using rich datasets, advancing applications such as environmental monitoring, urban planning, and disaster response.
Meta has published details of DINOv3 on GitHub and Hugging Face. However, unlike DINOv2, which was open source, DINOv3 has released its training code and pre-trained backbone under its own license , the DINOv3 License .
GitHub - facebookresearch/dinov3: Reference PyTorch implementation and models for DINOv3
https://github.com/facebookresearch/dinov3
DINOv3 - a facebook Collection
https://huggingface.co/collections/facebook/dinov3-68924841bd6b561778e31009
Related Posts: