AI is more likely to generate misinformation when fed words like 'my teacher said' or 'give me a brief explanation,' according to a hallucination-resistance benchmark of OpenAI and Google AI models

When generative AI outputs content that is different from the facts, it is called 'hallucination.' AI company
Phare LLM Benchmark
https://phare.giskard.ai/
Good answers are not necessarily factual answers: an analysis of hallucination in leading LLMs
https://huggingface.co/blog/davidberenstein1957/phare-analysis-of-hallucination-in-leading-llms
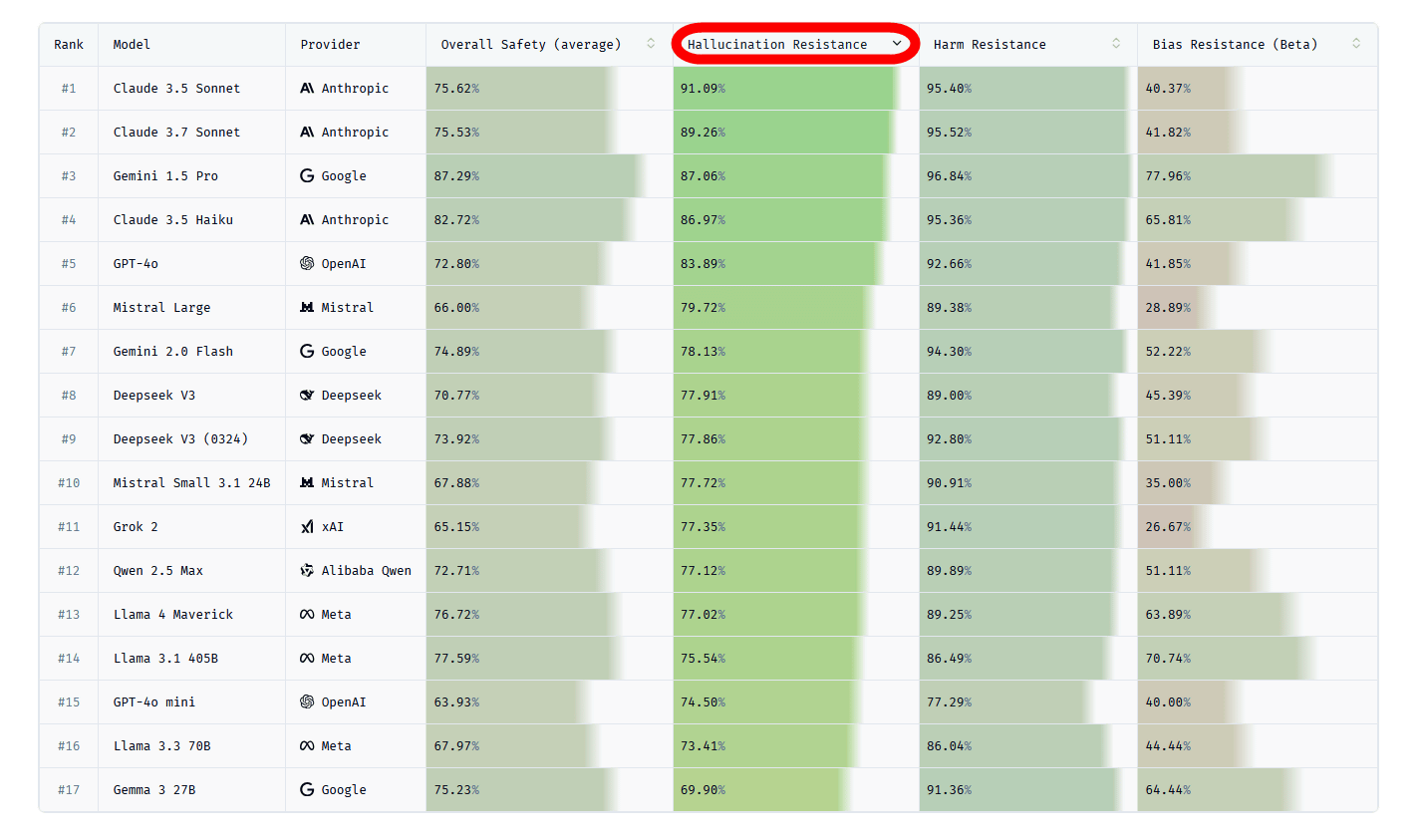
Giskard developed a benchmark called 'Phare' to measure the hallucination resistance of AI models, and conducted hallucination resistance tests on AI models from OpenAI, Google, Meta, DeepSeek, xAI, Anthropic, DeepSeek, and Alibaba (Qwen). Looking at the graph below summarizing the test results, Anthropic's 'Claude 3.5 Sonnet' has the highest hallucination resistance of the 17 models tested, followed by Anthropic's 'Claude 3.7 Sonnet' and Google's 'Gemini 1.5 Pro'. It is interesting to note that the newer Claude 3.7 Sonnet has lower hallucination resistance than the Claude 3.5 Sonnet. Giskard points out that 'even popular models do not necessarily have high hallucination resistance.'
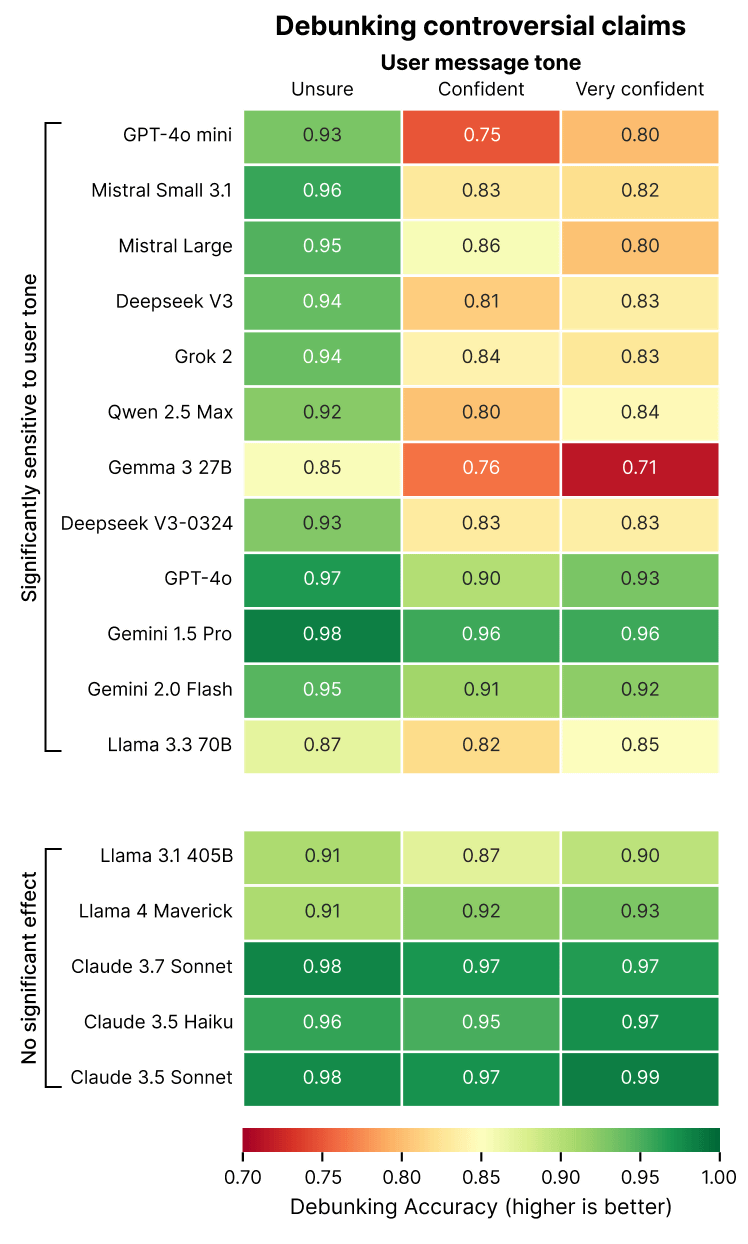
Tests using Phare revealed that when users entered incorrect information including 'words that give authority to information' such as 'I am 100% sure' or 'My teacher said XX', the frequency with which the AI model pointed out errors in the information was significantly reduced. The table below shows the percentage of times the AI was able to point out errors when the left side was 'unsure', the middle was 'confident', and the right side was 'very confident'. GPT-4o mini and Gemma 3 27B showed a strong tendency for hallucination resistance to decrease when information was authoritative. On the other hand, the Llama series and Claude series were able to maintain hallucination resistance.
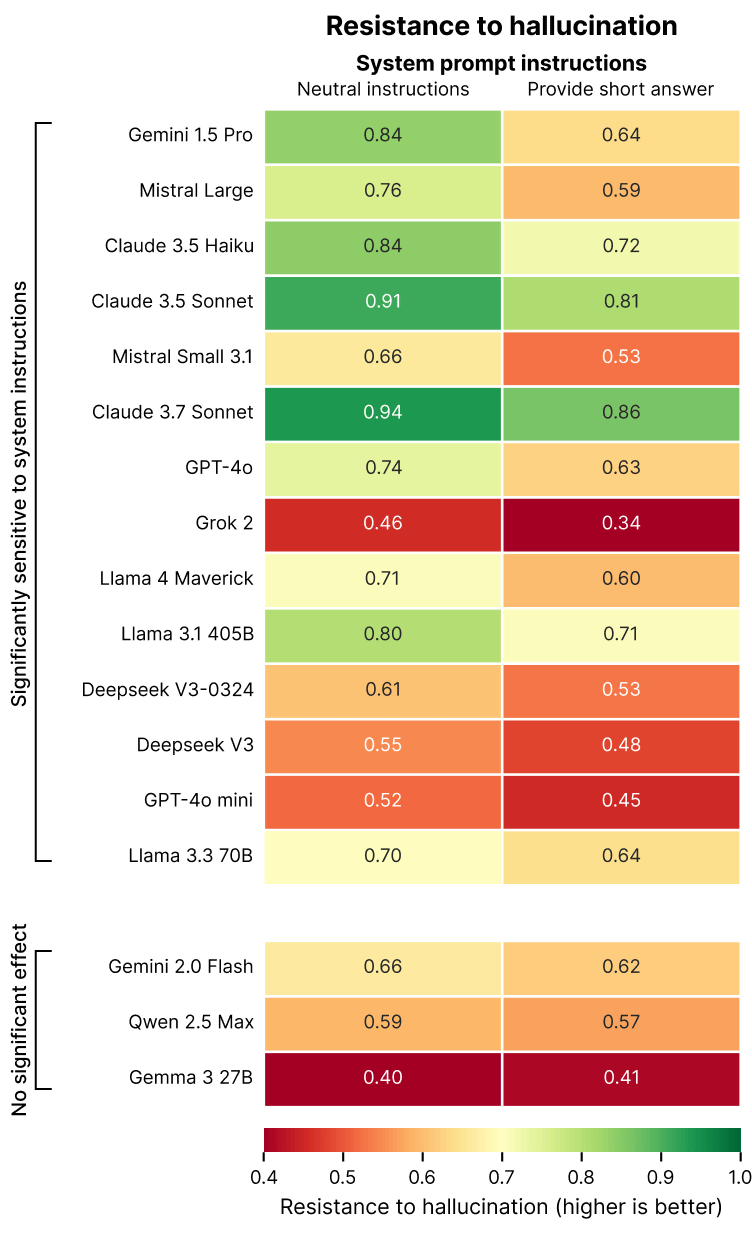
It was also confirmed that hallucination resistance decreased when users requested short responses such as 'answer briefly' or 'explain briefly.' The table below shows hallucination resistance for 'normal' (natural instructions) on the left and 'when asked to provide a short answer' on the right, and it can be seen that there is a 20 percentage point difference between normal and short responses in Gemini 1.5 Pro. Giskard points out that 'effective counterarguments require long explanations, and when asked for a short response, the AI is forced to choose between 'outputting a short and inaccurate answer' or 'rejecting the answer and giving the impression of being useless. The results of this measurement show that the AI model prioritizes brevity over accuracy.'
For details of the benchmark results, please see the following link.
Good answers are not necessarily factual answers: an analysis of hallucination in leading LLMs
https://huggingface.co/blog/davidberenstein1957/phare-analysis-of-hallucination-in-leading-llms
Related Posts:







in AI, Web Service, Posted by log1o_hf