Alibaba announces 'Qwen3', an inference model with higher performance than GPT-4o and o1, with the flagship model 'Qwen3-235B-A22B' having 235 billion parameters and 22 billion active parameters

' Qwen3 ' has been released in Qwen, a family of large-scale language models (LLMs) developed by
Qwen3: Think Deeper, Act Faster | Qwen
https://qwenlm.github.io/blog/qwen3/
GitHub - QwenLM/Qwen3: Qwen3 is the large language model series developed by Qwen team, Alibaba Cloud.
https://github.com/QwenLM/Qwen3
Alibaba unveils Qwen3, a family of 'hybrid' AI reasoning models | TechCrunch
https://techcrunch.com/2025/04/28/alibaba-unveils-qwen-3-a-family-of-hybrid-ai-reasoning-models/
The Qwen3 family, trained on a dataset of over 36 trillion tokens (1 million tokens equivalent to approximately 750,000 words), has eight models in order of decreasing parameter size: 'Qwen3-0.6B', 'Qwen3-1.7B', 'Qwen3-4B', 'Qwen3-8B', 'Qwen3-14B', 'Qwen3-32B', 'Qwen3-30B-A3B', and 'Qwen3-235B-A22B'. Six of these, 'Qwen3-0.6B', 'Qwen3-1.7B', 'Qwen3-4B', 'Qwen3-8B', 'Qwen3-14B', and 'Qwen3-32B', are Dense models, and two, 'Qwen3-30B-A3B' and 'Qwen3-235B-A22B', are MoE models.
The Qwen3-235B-A22B , the model with the largest parameter size in the Qwen3 family, has a parameter size of 235 billion and 22 billion active parameters. In benchmark evaluations of coding, mathematics, general functions, etc., it has achieved competitive results compared to other cutting-edge AI models from other companies, such as DeepSeek-R1, o1, o3-mini, Grok-3, and Gemini-2.5-Pro.
Introducing Qwen3!
— Qwen (@Alibaba_Qwen) April 28, 2025
We release and open-weight Qwen3, our latest large language models, including 2 MoE models and 6 dense models, ranging from 0.6B to 235B. Our flagship model, Qwen3-235B-A22B, achieves competitive results in benchmark evaluations of coding, math, general… pic.twitter.com/JWZkJeHWhC
Below is a table comparing the scores of various benchmarks for Qwen3-235B-A22B with competing models. Although the performance of the competing models is not significantly higher, it is clear that it has excellent performance. However, Qwen3-235B-A22B is not publicly available at the time of writing. Among the publicly available Qwen3 family models, the 'Qwen3-32B' has the largest parameter size. Qwen3-32B outperforms OpenAI's o1 in several benchmarks, including the coding benchmark LiveCodeBench.
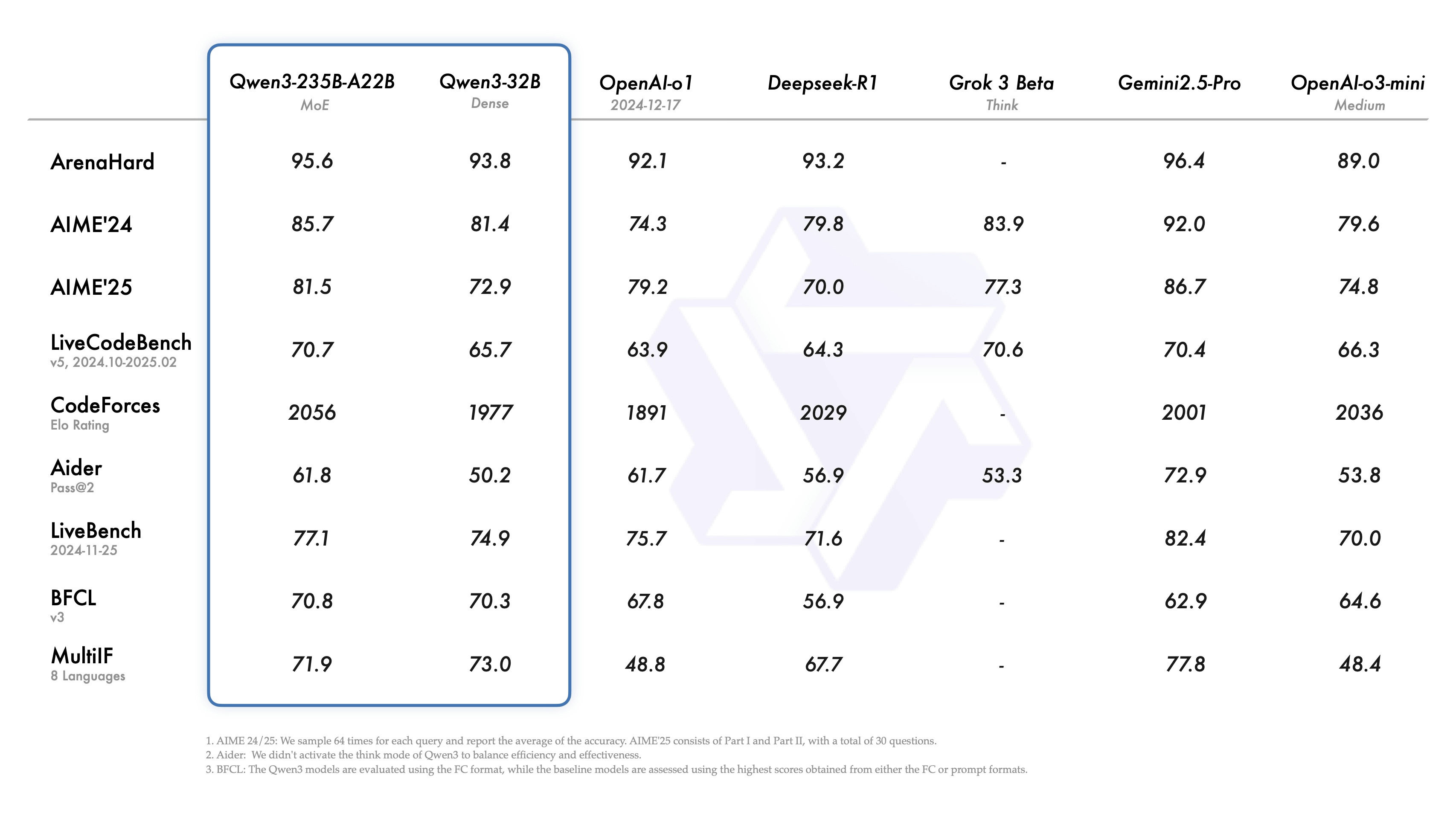
The small MoE model 'Qwen3-30B-A3B' has a total parameter size of 32 billion and 3 billion active parameters. Qwen3-30B-A3B achieves better performance than 'QwQ-32B', which has 10 times the active parameters. It also achieves better performance in almost all benchmarks compared to GPT-4o.
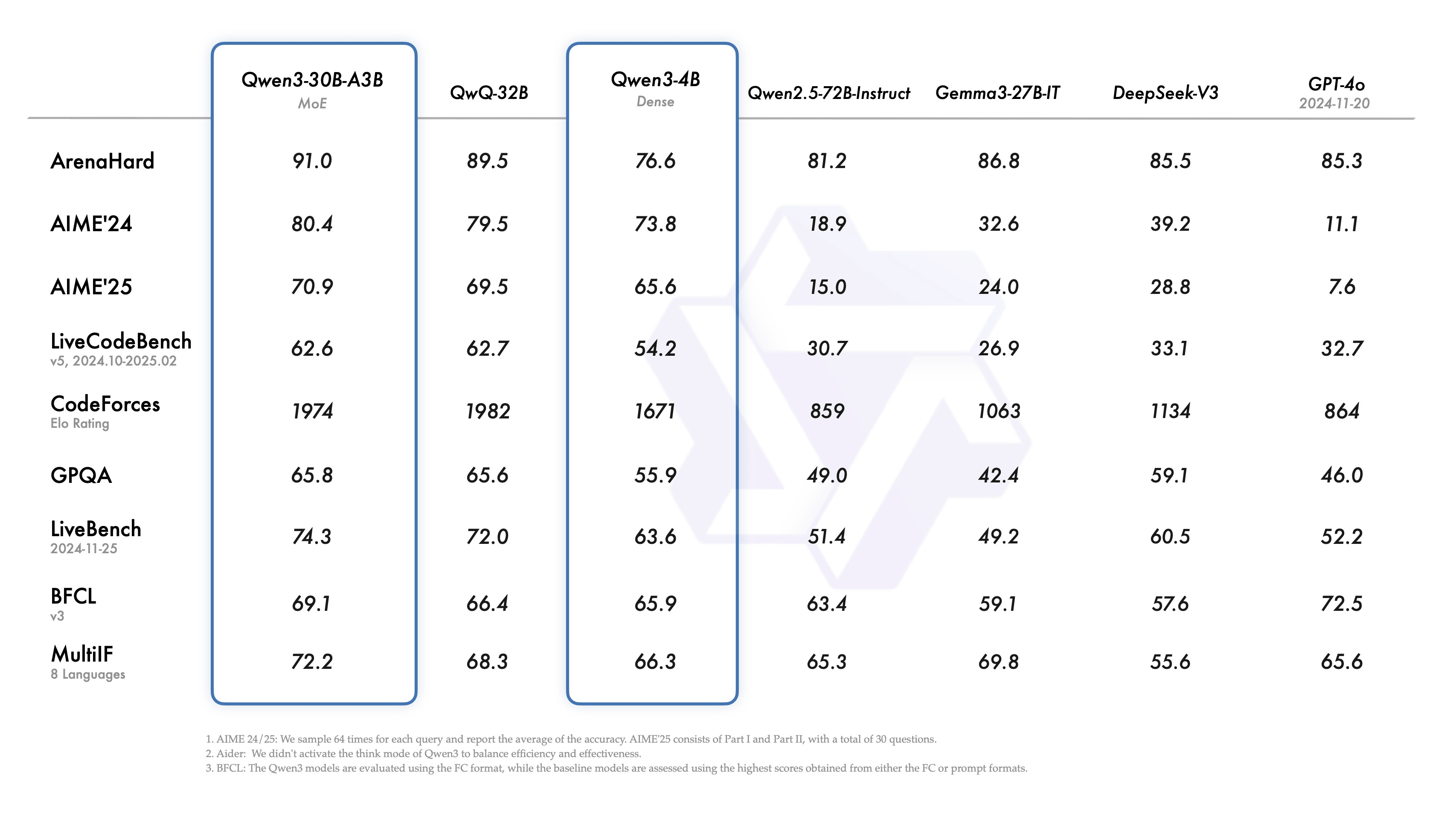
Furthermore, even small models such as the 'Qwen3-4B' (parameter size: 4 billion) are comparable in performance to the 'Qwen2.5-72B-Instruct' (parameter size: 72 billion) of the previous generation Qwen2.5 family, which has a larger parameter size.
Pre-trained models such as 'Qwen3-30B-A3B' are publicly available on platforms such asHugging Face , ModelScope , and Kaggle, and it is recommended to use frameworks such as SGLang or vLLM for deployment.
For local use, it is recommended to use tools such as Ollama , LM Studio , MLX , llama.cpp , and KTransformers , which will make it easier to integrate Qwen3 into your workflow whether in research, development, or production environments.
The Qwen3 family uses a hybrid approach to problem solving, supporting two modes: a 'thinking mode' that takes time to reason step by step before giving a final answer, and a 'no-thinking mode' that provides a quick, instantaneous response. The thinking mode is best suited for responding to complex problems that require deeper thought, while the no-think mode is best suited for responding to simple questions where speed is more important than thought. The hybrid approach can be turned on and off by including a special character (/think) or token in the prompt. It is on by default, and to turn it off, just enter the special character '/no_think' in the prompt.
With its hybrid approach, Qwen3 delivers scalable and smooth performance growth that directly correlates with the allocated compute inference budget, allowing users to more easily set task-specific budgets and achieve the optimal balance between cost efficiency and inference quality.
Qwen3 exhibits scalable and smooth performance improvements that are directly correlated with the computational reasoning budget allocated. This design enables users to configure task-specific budgets with greater ease, achieving a more optimal balance between cost efficiency and… pic.twitter.com/k0YcIO8V4f
— Qwen (@Alibaba_Qwen) April 28, 2025
Additionally, Qwen3 supports 119 languages and dialects, including Japanese. This extensive multilingual capability opens up new possibilities for international applications, meaning users all over the world can enjoy the power of Qwen3.
Qwen3 models are supporting 119 languages and dialects. This extensive multilingual capability opens up new possibilities for international applications, enabling users worldwide to benefit from the power of these models. pic.twitter.com/rwU9GWWP0K
— Qwen (@Alibaba_Qwen) April 28, 2025
The 119 languages and dialects supported by Qwen3 are as follows:
English, French, Portuguese, German, Romanian, Swedish, Danish, Bulgarian, Russian, Czech, Greek, Ukrainian, Spanish, Dutch, Slovak, Croatian, Polish, Lithuanian, Norwegian Bokmål, Norwegian Nynorsk, Persian, Slovenian, Gujarati, Latvian, Italian, Occitan, Nepali, Marathi, Belarusian, Serbian, Luxembourgish, Venetian, Assamese, Welsh, Silesian, Asturian, Chhattisgarhi, Awadhi Arabic, Maithili, Bhojpuri, Sindhi, Irish, Faroese, Hindi, Punjabi, Bengali, Oriya, Tajik, Eastern Yiddish, Lombard, Ligurian, Sicilian, Friulian, Sardinian, Galician, Catalan, Icelandic, Toscan, Albanian, Limburgish, Dari, Afrikaans, Macedonian, Sinhala, Urdu, Magahi, Bosnian, Armenian, Chinese (Simplified, Traditional, Cantonese), Burmese, Arabic (Mandarin, Najdi, Levantine, Egyptian, Moroccan, Mesopotamian, Taiji Adeni, Tunisian), Hebrew, Maltese, Indonesian, Malay, Tagalog, Cebuano, Javanese, Sundanese, Minangkabau, Balinese, Banjar, Pangasinan, Iloko, Waray (Philippines), Tamil, Telugu, Kannada, Malayalam, Turkish, North Azerbaijani, North Uzbek, Kazakh, Bashkir, Tatar, Thai, Lao, Finnish, Estonian, Hungarian, Vietnamese, Khmer, Japanese, Korean, Georgian, Basque, Haitian Creole, Papiamento, Kabbeldin, Tok Pisin, Swahili
We have also improved support for MCP by optimizing the Qwen3 model for coding and agent functionality. The following video shows an example of how Qwen3 thinks and interacts with its environment.
We have optimized the Qwen3 models for coding and agentic capabilities, and also we have strengthened the support of MCP as well. Below we provide examples to show how Qwen3 thinks and interacts with the environment. pic.twitter.com/7xFyJPp48g
— Qwen (@Alibaba_Qwen) April 28, 2025
All eight models in the Qwen3 family are released under the Apache 2.0 license.
Datasette developer Simon Willison said of Qwen3, 'It works directly with almost all popular LLM service frameworks and has been available since day one of release. This is an unusual level for an AI model release, and I don't know of any other AI model provider that has made this much effort. A common pattern is to mass-inject AI models for a single architecture into Hugging Face, and then wait for the community to catch up on quantization and conversion of all other models.' He praised Qwen3's excellent integration with LLM frameworks.
Related Posts: