Google announces 'Gemini 2.5 Flash,' claiming it is more cost-effective than OpenAI's 'o4-mini'

On April 17, 2025, Google announced that it has added the cost-effective ' Gemini 2.5 Flash ' to its
Start building with Gemini 2.5 Flash - Google Developers Blog
https://developers.googleblog.com/en/start-building-with-gemini-25-flash/
Gemini 2.5 Flash is now in preview
https://blog.google/products/gemini/gemini-2-5-flash-preview/
Gemini 2.5 Flash is now in preview!
— Google Cloud Tech (@GoogleCloudTech) April 17, 2025
⚡ Our lowest latency, most cost-efficient thinking model
???? Control reasoning to balance performance and budget
✅ Ideal for summarization, chat, data extraction, and more
Try on #VertexAI → https://t.co/8qZcCQzPXI pic.twitter.com/V31L4rr9Ow
Start building with Gemini 2.5 Flash
https://simonwillison.net/2025/Apr/17/start-building-with-gemini-25-flash/
The Gemini 2.5 Flash announced this time is one of the inference AI models 'Gemini 2.5' series released in March 2025. An inference model is a model that uses additional computing power and time to check facts and infer problems before giving an answer, enabling highly accurate output even in mathematical problems and coding. It is said to be possible to output with high accuracy even in complex tasks that require logical thinking, such as mathematical problems and coding, which conventional large-scale language models were weak at.
Google announces next-generation inference AI model 'Gemini 2.5', greatly improving inference and coding performance - GIGAZINE

Below is a table summarizing the various benchmark results for Gemini 2.5 Flash. Gemini 2.5 Flash has achieved high results in many benchmarks compared to Gemini 2.0 Flash , which was released in February 2025. In addition, the fee per million tokens for Gemini 2.5 Flash is $0.15 (about 21 yen) for input and up to $3.5 (about 500 yen) for output, which is cheaper than OpenAI's inference model 'o4-mini', which requires $1.1 (about 156 yen) for input and $4.4 (about 626 yen) for output, but the benchmark shows results close to o4-mini.
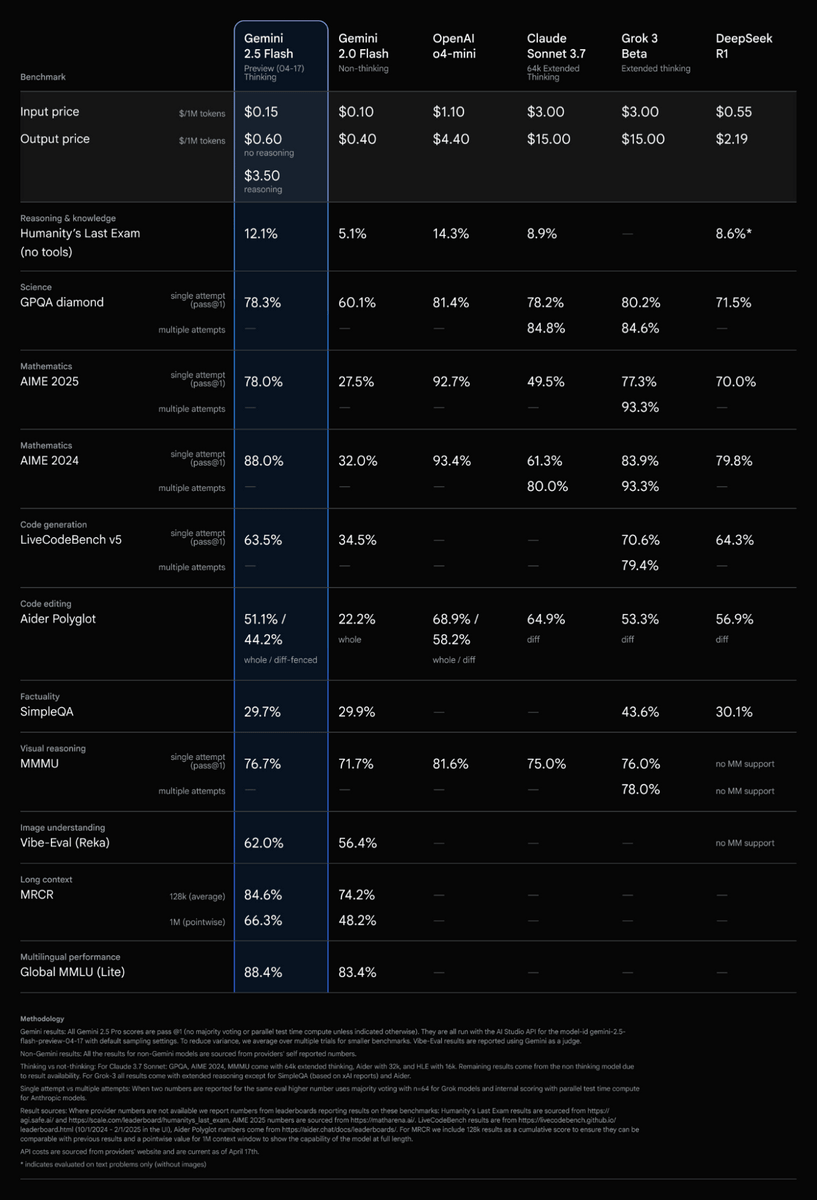
Google is promoting Gemini 2.5 Flash as the 'best cost-performance model,' and the graph below shows that Gemini 2.5 Flash is cheaper than other AI models, yet scores highly in
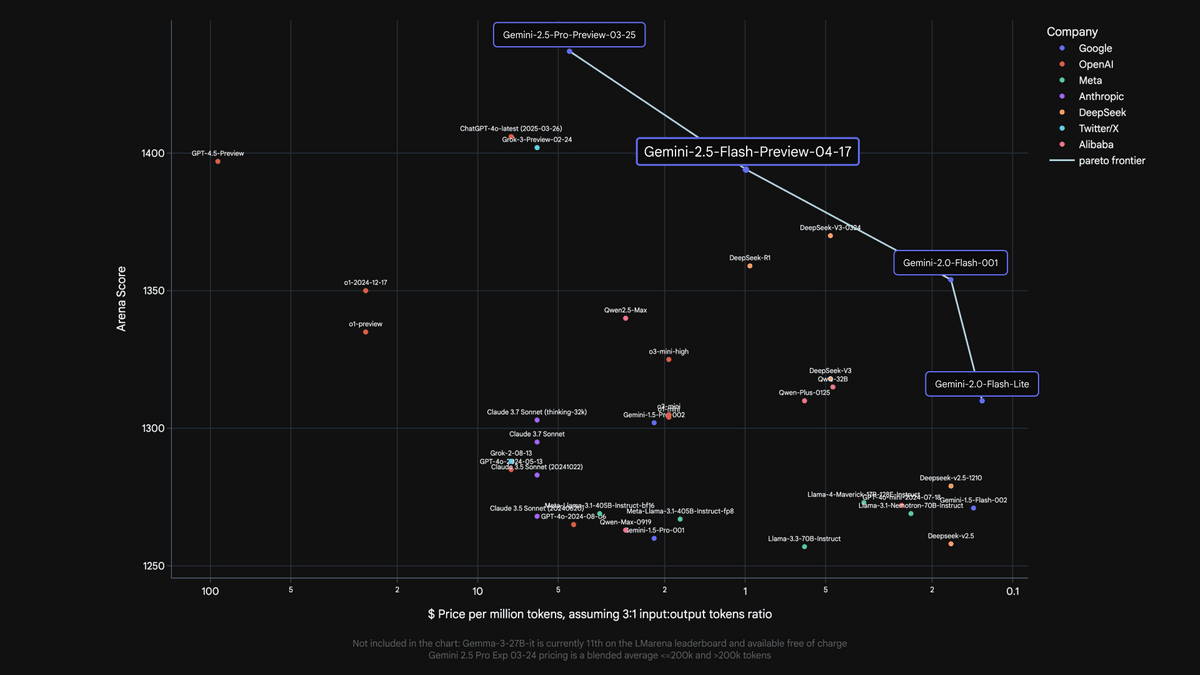
Gemini 2.5 Flash can be used with
Below is the image generated with the 'Reasoning' function turned on. According to Wilson, it cost 1.4933 cents (about 2.1 yen) to generate this image.

Next, the image generated with the 'Reasoning' function turned off looks like this. The cost of generation was 0.1025 cents (about 0.15 yen).

Below is the image generated when maximizing the resources spent on thinking. Of the 5174 output tokens, 3023 were used for inference, and the cost was 1.8111 cents (about 2.58 yen).

'One of the things I really appreciate about Gemini 2.5 Flash's approach to SVG is that it has a really good sense for CSS, comments, and general SVG class structure,' Wilson said. In addition, the message board site Hacker News commented , 'Gemini 2.5 Flash is the best multimodal tool for the price. Google has won the AI development race,' and 'Gemini's Flash series is fast, cost-effective, and perfect for end users.'
Related Posts: