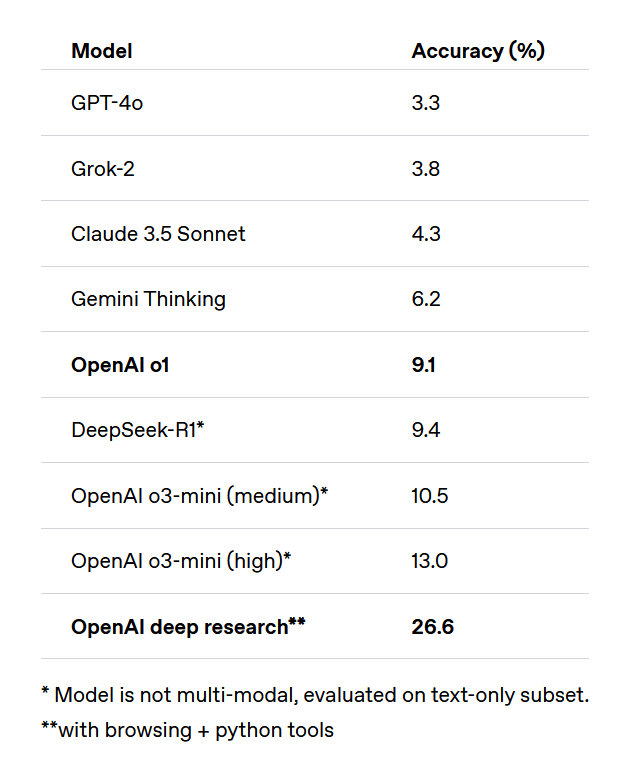
In the 'final test of humanity,' where the highest answer accuracy was about 9%, OpenAI's Deep Research achieved over 26%

It has been revealed that OpenAI's AI agent '
OpenAI's Deep Research smashes records for the world's hardest AI exam, with ChatGPT o3-mini and DeepSeek left in its wake | TechRadar
https://www.techradar.com/computing/artificial-intelligence/openais-deep-research-smashes-records-for-the-worlds-hardest-ai-exam-with-chatgpt-o3-mini-and-deepseek-left-in-its-wake
'The Last Test of Humanity' is a benchmark packed with specialized problems from a wide range of fields, including mathematics, humanities, and natural sciences, and is a selection of questions posed by university professors and famous mathematicians. In the pre-release test, it was reported that even OpenAI's latest model at the time, ' o1 ,' which had high inference capabilities, was only able to score 8.3%.
The most difficult AI test ever, 'The Last Test for Humanity,' has been released, consisting of 3,000 multiple-choice and short-answer questions - GIGAZINE

However, since the last human test was made public, many models have begun to record scores higher than the above. For example, DeepSeek's inference model ' R1 ', which has performance comparable to 'o1', achieved an accuracy of 9.4%, while OpenAI's inference model ' o3-mini ', released about two weeks after the release of 'R1', achieved an accuracy of 10.5%, and 'o3-mini-high', which has a higher inference level, achieved an accuracy of 13%.
Following this, a new AI agent from OpenAI called 'Deep research' came in second with a score of 26.6%, beating out the competition.
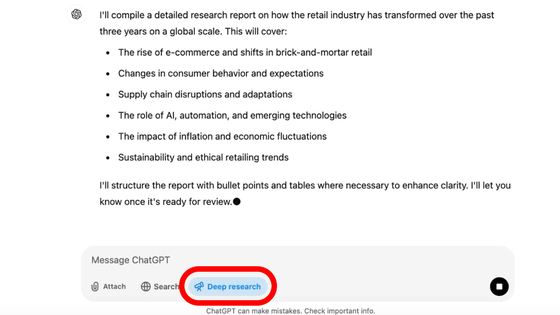
Deep research is an AI agent that searches for information on the internet and makes inferences, which sets it apart from existing chat services that only process information that has been pre-programmed.
OpenAI announces that ChatGPT will have a 'Deep research' feature that allows it to collect online information - GIGAZINE
The score of 26.6% was announced by OpenAI, but technology media TechRadar points out that it is a bit unfair because it is comparing AI with and without search functionality. However, it is surprising that a higher score than existing models was recorded in an evaluation test shortly after its release, and it shows how quickly AI is advancing.
On the other hand, if new evaluation tests are solved too quickly, there is a risk that the original purpose of quantitatively evaluating AI performance will not be achieved. Creating evaluation tests is costly, and if a test that was released at such a high cost and billed as 'the last one for humanity' is easily passed, the gap between AI performance and the difficulty of the evaluation test may widen further.
Regarding this point, the news site TIME points out that 'the speed at which evaluation tests are being created has not kept up with AI advances,' and adds, 'Effective evaluation tests remain difficult to design, costly and underfunded compared to their importance in identifying dangerous capabilities early. With leading labs releasing high-performance models every few months, the need for new tests to evaluate the models' capabilities has never been greater.'
AI models are getting smarter and smarter, so testing methods can't keep up - GIGAZINE

Related Posts:




in Software, Posted by log1p_kr